Linux System Debug SOP¶
REVISION HISTORY¶
| Revision No. | Description |
Date |
|---|---|---|
| 1.0 | 12/21/2023 |
前言¶
本文为FAE及软件开发相关人员而写,旨在介绍开发过程中客户遇到Linux系统相关问题时,如何自行进行初步排查,确定是Sigmastar SDK问题后再提供相关信息给RD分析。
1. 内存泄露问题¶
当系统在运行过程中出现OOM,或者在/proc/meminfo看到available或者free memory一直在减少,这种情况下可以先排查是否有内存泄漏的问题。
1.1 判断是user还是kernel内存泄漏¶
OOM打印的信息和meminfo的信息类似,从打印信息里面可以获取内存使用相关的数据。
OOM
OOM的 active_anon 和 inactive_anon 比较大,可以怀疑是应用层内存泄漏。
OOM的 slab_reclaimable 和 slab_unreclaimable 比较大,可以怀疑是内核内存泄漏。
/proc/meminfo
/proc/meminfo的 Active (anon)和 Inactive (anon)或者 AnonPages 比较大,可以怀疑是应用层内存泄漏。
/proc/meminfo的 SReclaimable 和 SUnreclaim 比较大,可以怀疑是内核内存泄漏。
1.2 应用层内存泄漏¶
1.2.1 应用没有显式调用malloc类接口¶
用户没有显式地调用malloc这些接口去申请内存,而是通过其他接口造成的内存泄漏,像是线程结束之后,没有主动回收线程。
1.2.1.1 /proc/$pid/maps 或者 pmap¶
如果是这种情况,可以通过看 /proc/$pid/maps 或者 pmap 中的8192K大小的匿名页是否有增长。(8192 是glibc 用户线程的栈默认大小,uclibc 则是 2044K,之所以没有 1024K 对齐,是因为使用了 4K 作为 guard page)
线程栈的泄漏:
- 粗略计算当前进程的所有线程栈的数量:
pmap pid | grep 8192 | wc -l,如果该数字一直变大,说明可能存在线程栈的泄漏 - 但是如果 app 仅比开始时多了几个线程栈但没有一直增长,且退出所有线程后仍发现比开始的线程栈多,则不一定是线程栈泄漏,可能是 glibc stack cache(默认是 40M,即 5 个线程)
- 一般是线程退出后没有
pthread_join()或线程退出前没有调用pthread_detach()导致的
1.2.1.2 /proc/$pid/status¶
也可以通过看 /proc/$pid/status ,查看Threads字段是否有增长来判断。
1.2.2 tcmalloc heap profile¶
如果 app 没有退出逻辑,无法用 asan 扫描内存泄漏,可以考虑使用 tcmalloc
所用到的库需要从 gperftools 和 libunwind 下载 release 版本并解压:
# 编译 libunwind,so 位置是 build/lib/libunwind.so.8
./configure --host=arm-linux-gnu CXX=arm-linux-gnueabihf-g++ CC=arm-linux-gnueabihf-gcc --enable-cxx-exceptions --disable-tests --prefix=$PWD/build
make install
# 编译 gperftools,so 位置是 build/lib/libtcmalloc.so.4.5.16
./configure --host=arm-linux-gnu CXX=arm-linux-gnueabihf-g++ CC=arm-linux-gnueabihf-gcc --prefix=$PWD/build \
CPPFLAGS="-I$PWD/../libunwind-1.8.1/build/include" \
CFLAGS="-I$PWD/../libunwind-1.8.1/build/include" \
LDFLAGS="-L$PWD/../libunwind-1.8.1/build/lib" LIBS="-lunwind"
make install
app 需要使用 -g 编译,板子上的 app 可以 strip,但是需要保留 .ARM.exidx 段,可以通过 arm-linux-gnueabihf-readelf -S app 去确认,本地用 pprof 分析用的 app 必须要有 -g(因为 backtrace unwind 只需要 .ARM.exidx 段得到每个函数的地址,但是 pprof 分析结果时需要打印行号,则需要 app 要有调试信息才能看到行号)
还有就是如果是 uclibc,除了 -g,还需要添加 -funwind-tables,因为貌似 uclibc toolchain 默认不会生成 .ARM.exidx 段
编译 app 注意事项:
- app 需要使用
-g编译,因为 pprof 分析结果时需要用来看行号 - 板子上的 app 可以 strip,但是需要保留
.ARM.exidxsection,可以通过arm-linux-gnueabihf-readelf -S app去确认 - 本地用 pprof 分析用的 app 必须要有
-g(因为记录 backtrace 只需要函数地址信息,但是 pprof 分析结果需要打印函数名,需要有调试信息) - 如果是 uclibc toolchain,除了
-g,还需要添加-funwind-tables,因为貌似 uclibc toolchain 默认不会生成.ARM.exidx
运行 app(记住需要重命名为 libunwind.so.8)增加以下环境变量:
# 先把 libunwind.so.8 和 libtcmalloc.so.4.5.16 拷贝到设备上
mkdir /mnt/mmc/profile
export HEAPPROFILESIGNAL=12 HEAPPROFILE=/mnt/mmc/profile/profile UNW_ARM_UNWIND_METHOD=4
# 也可以加上 HEAP_PROFILE_MMAP=true HEAP_PROFILE_MMAP_LOG=yes 去抓 app mmap 信息,但是无法抓到线程栈的 mmap,因为 glibc 调用的是 __mmap
export LD_LIBRARY_PATH=/dir/to/libunwind.so.8 # libunwind.so.8 所在的目录
LD_PRELOAD=/path/to/libtcmalloc.so.4.5.16 ./app
运行过程中隔一段时间去 kill -12 pid 就会在 /mnt/mmc/profile/ 目录下生成某一时刻的 malloc 使用情况
在 host 端分析结果(这里的 app 需要是带 -g 且没有 strip 的:
pprof --lines --text --show_bytes app profile.0001.heap --lib_prefix=$PWD,如果不加--show_bytes显示的是 MB- 如果第一步的结果里面只有地址没有函数名,那可能需要拷贝对应的未 strip 的 so 到 host,比如
/config/lib/libxx.so就是mkdir ./config/lib并拷贝 - 第一步的输出结果主要看第一列,第一列是每个函数已分配但是未释放的字节数
更直接的方法是对比 2 次结果:pprof --lines --text --show_bytes [app] profile.0002.heap --lib_prefix=$PWD --base=profile.0001.heap,如果出现某一行第一列的值增长很明显,则说明对应行的函数可能有内存泄漏
1.3. 内核内存泄漏¶
1.3.1 slab内存¶
常见的,OOM看slab_reclaimable 和 slab_unreclaimable,meminfo看SReclaimable和SUnreclaim,特别是unreclaim的内存。如果这些项耗内存过多,可以开启kernel原生的slub debug机制做debug。
slub debug配置项:
CONFIG_SLUB=y
CONFIG_SLUB_DEBUG=y
CONFIG_SLUB_DEBUG_ON=y
CONFIG_SLUB_STATS=y
# 定位是 slab 中哪一个内存泄漏,泄漏的通常是 active_objs 不断变大的那一项
cat /proc/slabinfo
slabinfo - version: 2.1
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
mi_vif_internal 0 18 448 18 2 : tunables 0 0 0 : slabdata 1 1 0
mi_vif_internal 0 18 448 18 2 : tunables 0 0 0 : slabdata 1 1 0
mi_scl_internal 8 20 1600 20 8 : tunables 0 0 0 : slabdata 1 1 0
cmdq_pool 5 20 400 20 2 : tunables 0 0 0 : slabdata 1 1 0
mi_sys_ringpool 0 0 576 28 4 : tunables 0 0 0 : slabdata 0 0 0
mi_sys_bufhandl 520 576 512 16 2 : tunables 0 0 0 : slabdata 36 36 0
mi_sys_meta_buf 0 0 1152 28 8 : tunables 0 0 0 : slabdata 0 0 0
mi_sys_cust_all 0 0 1152 28 8 : tunables 0 0 0 : slabdata 0 0 0
g_miSysChunkCac 540 616 576 28 4 : tunables 0 0 0 : slabdata 22 22 0
g_miSysMmaAlloc 34396 34408 1408 23 8 : tunables 0 0 0 : slabdata 1496 1496 0
# xxx 是上面的 name,比如 g_miSysMmaAlloc
cat /sys/kernel/slab/xxx/alloc_calls
1.3.2 vmalloc内存¶
在meminfo的VmallocUsed可以查看通过vmalloc申请内存的使用情况。
虽然有些kernel版本不会对这个项进行统计,也可以通过以下方法查看相关的内存使用:
cat /proc/vmallocinfo
Note: 主要对比vmallocinfo中pages的分配数量,其中vmap的page分配数量可以忽略。
1.3.3 通过CamOs API申请的内存¶
通过CamOs API申请的内存可能是上面提到的slab内存,也可能是vmalloc申请的内存。
对于这部分内存的使用,可以使用监测CAM OS API分配内存的机制。
机制打开的方法:
-
在kernel打开宏 CONFIG_TRACE_CAM_OS_MEM
-
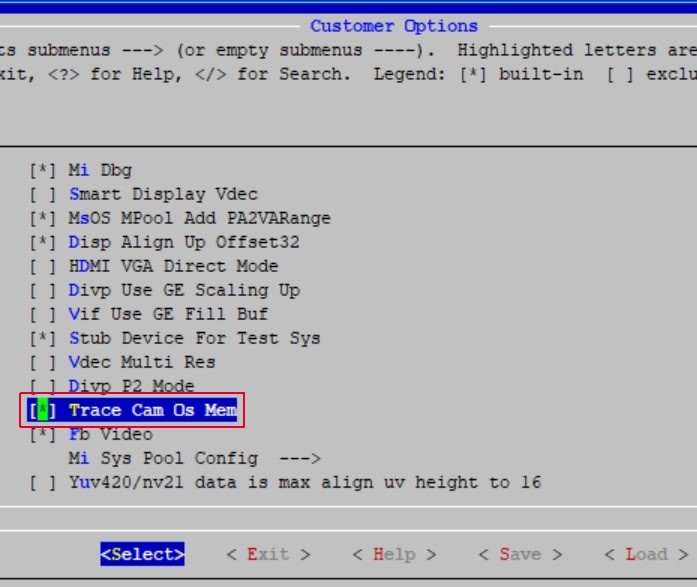
通过Alkaid的menuconfig选项打开TRACE_CAM_OS_MEM功能,在project路径下执行make menuconfig,选项路径:Customer_Options -→> Trace Cam Os Mem ,如下图:
该功能会在以下API中记录trace信息:
CamOsMemAlloc
CamOsMemAllocAtomic
CamOsMemCalloc
CamOsMemCallocAtomic
CamOsMemCacheAlloc
CamOsMemCacheAllocAtomic
CamOsContiguousMemAlloc
如果enable成功,在平台的/proc/mi_modules/common路径会有 mem_filter 和 mem_stat 两个proce entry
cat /proc/mi_modules/common/mem_filter:可以看到能够监测的模块。echo trace 5 > /proc/mi_modules/common/mem_filter:可以选择需要关心的模块以监测内存消耗,比如这里选择模块MI_SYS,序号为 5。echo trace 40 > /proc/mi_modules/common/mem_filter:设置大于39的数值就可以查看所有模块的内存监测信息,比如这里设置40。echo showall 1 > /proc/mi_modules/common/mem_filter:定位模块调用CAM OS API申请内存的地方
| 信息条目 | 意思 |
|---|---|
| ModuleName | 被监测的模块 |
| TotalSize | 对应模块所申请的内存大小 |
| TraceInfo | 每做一个记录所耗的kernel内存大小,属于本功能所耗的内存 |
| TotalCount | 本次监测统计一共记录的个数 |
| TraceCost | 本功能在本次监测统计所耗的内存,等于TraceInfo 乘以TotalCount |
| HighTotal | 在本次统计中,各个模块申请内存的总和峰值 |
| CamTotal | 在本次统计中,各个模块申请内存的总和 |
如果需要查看所有模块申请内存的函数信息,可以用以下几条命令:
echo trace 10 > /proc/mi_modules/common/mem_filter
echo showall 1 > /proc/mi_modules/common/mem_filter
# 23 表示中间省略1次同样API申请同样size内存的打印。
cat /proc/mi_modules/common/mem_stat
--------------------------- CamOsMemory Usage state ---------------------------
Function Caller Ptr BytesReq
--------------------------------------------------------------------------------
[kernel]:
_CamProcCreateEntryNode+0x6f/0x12a c2199a00 38
...(23)
0xbfdc907f c20a0200 d0
...(1)
_CamProcCreateEntryNode+0x6f/0x12a c1f79100 38
.....
通过对比 mem_stat 前后 2 次的结果就可以得到内存泄漏的位置
1.3.4 kmemleak工具¶
对于kernel内存泄漏问题,可以用kernel原生的工具kmemleak做分析。
kmemleak打开方法:
Kernel hacking → Memory Debugging → Kernel memory leak detector
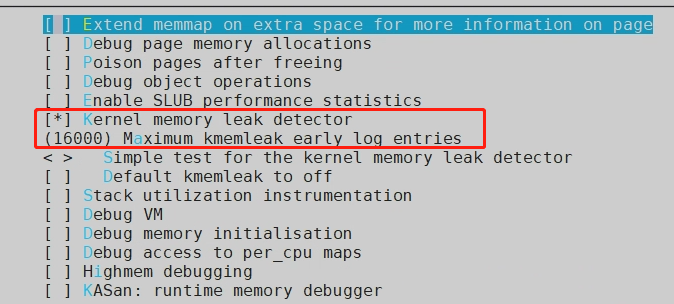
kmemleak打开对应的配置项:

1)清除kmemleak历史记录,以便记录新数据:
echo clear > /sys/kernel/debug/kmemleak
2)使能kmemleak进行内存泄漏检测扫描:
echo scan > /sys/kernel/debug/kmemleak
echo scan=n > /sys/kernel/debug/kmemleak 设置n秒内自动记忆扫描,默认600s
3)查看kmemleak内存泄漏检测结果:
cat /sys/kernel/debug/kmemleak
运行步骤:
1)echo clear > /sys/kernel/debug/kmemleak //清除缓存
2)echo scan=10 > /sys/kernel/debug/kmemleak //开启扫描,设置扫描时间间隔为10s
3)insmod kmemleak_test.ko
4)cat /sys/kernel/debug/kmemleak
unreferenced object 0xe1be4000 (size 4000):
comm "insmod", pid 869, jiffies 4294948352 (age 31.890s)
hex dump (first 32 bytes):
0d 00 00 00 04 00 00 00 ff ff ff ff ad 00 00 00 ................
01 00 00 00 02 00 00 00 ec 51 75 bf 98 01 00 00 .........Qu.....
backtrace:
[<c0092a8b>] __vmalloc_node+0x2f/0x38
[<c0092ab7>] vmalloc+0x23/0x30
[<bf75501f>] kmemleak_test+0x1e/0x54 [kmemleak_test] //gdb可定位到vmalloc行
[<bf75700d>] 0xbf75700d
[<c00095bf>] do_one_initcall+0xcf/0x104
[<c005ebc1>] do_init_module+0x39/0x12c
[<c005ffc7>] load_module+0x12d1/0x13b6
[<c0060159>] SyS_init_module+0xad/0xb8
[<c000d2e1>] ret_fast_syscall+0x1/0x4c
[<ffffffff>] 0xffffffff
注意:kernel config 打开 CONFIG_TRACE_CAM_OS_MEM 后,kmemleak 会追踪不到 cam os api 的内存泄漏,因为所有 camos 分配内存的指针都会被添加到 hash list 里面,如果有内存泄漏,hashlist 中仍会存在泄漏内存的指针,kmemleak 扫描内存时也会扫描到该指针,导致 kernel 误认为没有内存泄漏
1.3.5 使用page_owner¶
当以上方法都查不到kernel memleak的root cause时,可以采用kernel原生的page owner机制,它记录了每个申请page的owner,以及记录了owner申请page的callstack。
打开page_owner机制需要的配置:
- 添加kenel配置 CONFIG_PAGE_OWNER=y
- 在bootargs参数添加 page_owner=on
功能开启后我们可以在proc中看到如下节点:
/sys/kernel/debug/page_owner
之后的使用教程我们就可以参考:
Documentation/vm/page_owner.rst
...
1) Build user-space helper::
cd tools/vm
make page_owner_sort
2) Enable page owner: add "page_owner=on" to boot cmdline.
3) Do the job what you want to debug
4) Analyze information from page owner::
cat /sys/kernel/debug/page_owner > page_owner_full.txt
./page_owner_sort page_owner_full.txt sorted_page_owner.txt
See the result about who allocated each page
in the ``sorted_page_owner.txt``.
编译page_owner_sort排序工具,然后cat节点最后排序。然后肉眼看一大堆数据
下面就是page_owner的一个输出结果:
/mnt/slab_diff/0804 # tail -n 20 ./sorted_page_owner2.txt
1 times:
Page allocated via order 8, mask 0x52dc0(GFP_KERNEL|__GFP_NOWARN|__GFP_NORETRY|__GFP_COMP|__GFP_ZERO), pid 2298, ts 7180405565150 ns, free_ts 7170863960659 ns
get_page_from_freelist+0x1b5/0x402
__alloc_pages_nodemask+0xc9/0x5de
kmalloc_order+0x1f/0x44
kvmalloc_node+0x39/0x88
CamOsMemCalloc+0x35/0x44
IqInit+0x11/0x8c [mi_isp]
CameraIspAlgo_3A_IQ_Init+0x481/0x53e [mi_isp]
CameraCreateIspInstance+0x29b/0x2f8 [mi_isp]
MHalVpeCreateIspInstance+0xff/0x158 [mi_isp]
MI_ISP_DRVCFG_CreateInstance+0xb9/0x19c [mi_isp]
MI_ISP_IMPL_CreateChannel+0x619/0x6c4 [mi_isp]
MI_ISP_IOCTL_CreateChannel+0x31/0x74 [mi_isp]
MI_DEVICE_Ioctl+0xfd/0x1f0 [mi_common]
vfs_ioctl+0x11/0x1c
sys_ioctl+0x8b/0x4b2
ret_fast_syscall+0x1/0x5c
每个order(页框)对应的size如下:
- order 0: 4KB
- order 1: 8KB
- order 2: 16KB
- order 3: 32KB
- order 4: 64KB
- order 5: 128KB
- order 6: 256KB
- order 7: 512KB
- order 8: 1MB
- order 9: 2MB
也是跟buddyinfo页框数量的顺序一一对应的:
cat /proc/buddyinfo
Node 0, zone Normal 28 22 15 14 5 7 10 5 5 128
根据剩余页框数量我们可以计算出meminfo中的LowFree大小了。MemFree=HighFree+LowFree 所以我们可以计算出内存剩余量。
回到上面的page_owner结果,我们可以信息很清楚的看到:Page allocated via order 8, mask 0x52dc0(GFP_KERNEL|__GFP_NOWARN|__GFP_NORETRY|__GFP_COMP|__GFP_ZERO), pid 2298, ts 7180405565150 ns, free_ts 7170863960659 ns
这个页框的信息:
- order 8 申请了1M内存
- mask 掩码是多少
- pid 是多少。
ts表示分配该页面的时间戳,即页面被分配的时间点。free_ts表示最后一次释放该页面的时间戳,即页面最后一次被释放的时间点。
通过比较这两个时间戳,您可以计算出页面从分配到最后一次释放所经过的时间。这在分析页面的使用情况、内存回收等方面可能会有用。
我们可以看到free_ts小于ts 那就说明申请了没释放。 根据调用栈我们看到是IqInit时申请了1M内存没有释放。
2. CPU loading高问题¶
2.1 top¶
top 可以简单分析总体的 cpu loading 和内存,确认是哪个线程或进程的 cpu loading 较高
输入 top 后再按 1,就可以列出每个 cpu 的 loading:
- us 表示 user,sy 表示 system,hi 表示 hard irq,si 表示 soft irq,st 表示 steal time (hypervisor)
- 通过 top CPUx 那一行可以定位到非线程上下文的 cpu loading 高的问题,比如 si 和 hi 过高也会导致线程调度不及时
Mem: 74864K used, 1720804K free, 853776K shrd, 0K buff, 17924K cached CPU0: 0.0% us 5.3% sy 0.0% ni 94.6% idle 0.0% io 0.0% hi 0.0% si 0.0% st CPU1: 0.1% us 3.5% sy 0.0% ni 96.2% idle 0.0% io 0.0% hi 0.0% si 0.0% st CPU2: 0.0% us 0.0% sy 0.0% ni 100% idle 0.0% io 0.0% hi 0.0% si 0.0% st CPU3: 0.7% us 1.5% sy 0.0% ni 97.6% idle 0.0% io 0.0% hi 0.0% si 0.0% st Load average: 14.05 14.05 14.01 1/108 1028 PID PPID USER STAT VSZ %VSZ CPU %CPU COMMAND 996 993 root S 58088 3.2 1 1.2 ./prog_vif_isp_scl_ut param_snr0_venc.ini 1003 2 root DW 0 0.0 1 1.0 [isp0_P0_MAIN] 942 2 root DW 0 0.0 1 0.1 [IspMidThreadWq] 997 2 root DW 0 0.0 0 0.1 [vif0_P0_MAIN] 1028 1014 root R 2432 0.1 2 0.1 top 1009 2 root DW 0 0.0 2 0.0 [venc0_P0_MAIN] 937 2 root DW 0 0.0 0 0.0 [IspDriverThread] 12 2 root IW 0 0.0 3 0.0 [rcu_preempt]
2.2 perf¶
top 只能定位到大概出问题的位置,但是无法定位造成 cpu loading 高的具体位置
需要用到 perf 和 FlameGraph 去定位具体的代码位置:
# 将 perf 拷贝到设备上执行以下 2 条命令,生成的 perf.unfold 拷贝出来
# -a 表示 --all-cpus,-g 表示抓取 kenrel 和 user;sleep 1 表示 1 秒后退出抓取,可以加大该值加长抓取时间
perf record -a -g sleep 1
perf script -i perf.data > perf.unfold
# 使用抓到的 perf 数据生成火焰图
# https://github.com/brendangregg/FlameGraph.git,进入该项目的目录下后执行命令
./stackcollapse-perf.pl ./perf.unfold > report.data && ./flamegraph.pl report.data > report.svg
若想要抓到的部分是 ? (unknown) 或地址,则可能需要针对对应的 app binary 和 so 开启 -g 去编译
2.3 瞬时 cpu loading 高的问题¶
由于 FlameGraph 显示的是一段时间内的 cpu loading,但是无法观察到瞬时升高的 cpu loading
这里推荐使用 flamescope,依赖只有 python,因此可以跑在 linux 或 windows:
# 在设备上抓取的方式一致
perf record -a -g sleep 1
perf script -i perf.data > perf.unfold
# 环境搭建
git clone https://github.com/Netflix/flamescope
cd flamescope
# master 分支的 flamescope 有问题,需要替换 tag v0.2.0 的 app/public
git checkout -b v2.0.0 v2.0.0
cp app/public ..
git checkout master
cp -r ../public app
pip install -r requirements.txt
# 将抓取的数据拷贝到 example 进行可视化
cp [path/to/perf.unfold] example/
python run.py
打开 127.0.0.1:5000 再打开 perf.unfold,就能看到 x 轴为秒,y 轴为毫秒的图,点击其中任意 2 个点既可打开这段时间内的火焰图
3. 死锁问题¶
3.1 死锁概念¶
死锁是指多个进程(线程)因为长久等待已被其他进程占有的的资源而陷入阻塞的一种状态。当等待的资源一直得不到释放,死锁会一直持续下去。死锁一旦发生,程序本身是解决不了的,只能依靠外部力量使得程序恢复运行,例如重启,看门狗复位等。
3.2 互斥死锁分析¶
主要分为 D 状态死锁和 R 状态死锁。
3.2.1 D 状态死锁分析¶
D 状态死锁指的是 进程等待 I/O 资源无法得到满足,长时间(系统默认配置 120 秒)处于 TASK_UNINTERRUPTIBLE 睡眠状态。 可以通过mi_sys的 show_threads 命令来定位具体问题。 使用方式: 要在死锁出现的现场:
-
新建一个窗口,在这个窗口中:
cat /proc/kmsg这一步很重要,因为抓取ksmg的log相比起串口log要齐全。
-
在另外的窗口中:
echo show_threads > /proc/mi_modules/mi_sys/mi_sys0 -
分析kmsg的输出
3.2.2 R 状态死锁分析¶
进程长时间(系统默认配置 60 秒)处于 TASK_RUNNING 状态垄断 CPU 而不发生切换,一般情况下是进程关抢占或关中断后长时候执行任务、死循环,此时往往会导致多 CPU 间互锁,整个系统无法正常调度,导致喂狗线程无法执行,无法喂狗而最终看门狗复位的重启。该问题多为原子操作,spinlock 等 CPU 间并发操作处理不当造成。后面所介绍的 Lockdep 死锁检测工具检测的死锁类型就是 R 状态死锁。
3.3 自旋死锁分析¶
spinlock死锁大致可以分为soft lockup和hard lockup。
soft lockup: 指CPU运行在kernel space,并且超过一定时间都没有发生过任务调度。
hard lockup:指CPU超过指定时间,都没有发生过interrupt。 对于不同lockup,有不同解决分析手段。
3.3.1 soft lockup分析¶
针对 soft lockup 可以使用linux kernel的soft lockup detector。
-
原理 soft lockup detector会为每一个CPU启动一个watchdog thread,并设置调度属性,只允许在对应的CPU上执行,这个thread的作用类似hardware watchdog,喂狗(更新时间戳watchdog_touch_ts),如果这个thread有被CPU正常的调度,则watchdog_touch_ts会被更新,从而不会触发soft lockup报警。
检查是否喂狗超时,是在CPU arch timer中断处理函数里面,如果系统异常,如:某个thread使用了preempt_disable()并长时间没有调用preempt_enable(),就会导致喂狗的thread得不到CPU执行,就会导致超时。
-
使用方式 Kernel Config Option:
CONFIG_LOCKUP_DETECTOR=yKernel重编后,重烧开机去复现问题,抓取log进行分析。
3.3.2 hard lockup分析¶
对于 hard lockup ,目前原生 ARM Linux 上并没有其他很好的Feature来定位问题。可以通过下面的 Trace32 或者 Lockdep 来定位问题。
3.3.3 Trace32分析¶
除了上述方案外,可以接入Trace32,看下各个core跑的真实上下文,最为直观。 在连接Trace后,输入命令'frame',默认弹出core0的堆栈信息,通过右下角切换core,来查看想要观察的core上下文。 更多具体使用方法参见Trace32培训。
3.4 死锁通用分析方法¶
无论是自旋锁还是互斥(不包括信号量),对于可以再复现的场景,可以打开Linux内核的一个检测死锁的feature "Lockdep"。用后面介绍的方法打开Lockdep,然后复现问题,分析log得出导致死锁的真凶。
3.4.1 Lockdep 简介¶
Linux内核提供死锁调试模块Lockdep,跟踪每个锁的自身状态和各个锁之间的依赖关系,经过一系列的验证规则来确保锁之间依赖关系是正确的。 Lockdep检测的锁包括spinlock、rwlock、mutex、rwsem的死锁,锁的错误释放,原子操作中睡眠等错误行为。
3.4.2 Lockdep 使用¶
下面两种方式任选其一,推荐使用2.比较方便快捷。
-
单独编译Kernel打开 在menuconfig或者defconfig中打开如下选项:
CONFIG_DEBUG_LOCK_ALLOC=y CONFIG_PROVE_LOCKING=y CONFIG_LOCKDEP=y CONFIG_LOCK_STAT=y CONFIG_DEBUG_LOCKDEP=y CONFIG_TRACE_IRQFLAGS=y CONFIG_DEBUG_ATOMIC_SLEEP=y -
整包编译Alkaid打开 可参见L3 WIKI《编译alkaid debug版本》,编译整个image时带上DEBUG=4,即:
make image DEBUG=4 -jN
4. 踩内存问题¶
崩溃是踩内存问题最为常见的现象(包括访问无效指针,断言失败,打印的变量值不符合预期等)
4.1 sdk 对齐¶
若调用 mi api 时发现怪异表现(比如在 kernel 打印的值和 user 拿到的不一样),先去排查 release sdk 是否对齐了,包括头文件、ko、so 等
若已经确认对齐后还是会有问题,再确认是否还有预编译的算法库 so 等单独使用了静态链接的 sdk 的 .a,确认方法如下:
# MI_SYS_ChnInputPortGetBufPa 只是一个例子,具体应该是要改成表现怪异的 mi api
# 若能在 so 里面找到相同的 api(T 表示 test 段),证明 libxxxx.so 链接了 sdk 的 .a,需要用新的 sdk 去编译 libxxxx.so
arm-linux-gnueabihf-nm libtest.so | grep MI_SYS_ChnInputPortGetBufPa
0000000000002a20 T MI_SYS_ChnInputPortGetBuf
arm-linux-gnueabihf-nm libxxxx.so | grep MI_SYS_ChnInputPortGetBufPa
0000000000002a20 T MI_SYS_ChnInputPortGetBuf
4.2 asan (userspace)¶
userspace 常见的踩内存现象:
- SIGSEGV:空指针,指针未初始化就使用,内存越界
- libc 或非常稳定的第三方库出现判断失败导致 abort:可能是内存越界或者 used after free
- 没有 crash 但是某些变量的值不正常:可能是内存越界或者 used after free
userspace 定位踩内存问题最有效的工具就是 asan
4.2.1 asan 的基本使用方法¶
userspace 使用 asan 扫描踩内存问题:
- 需要针对所有编译的库和 binary 开启 3 个编译选项
-g -fsanitize=address -fno-omit-frame-pointer;也可以不加-fno-omit-frame-pointer但需要 strip 时保留.ARM.exidxsection - 打包可以去 strip,编译一定要有 -g 并保留未 strip 的 binary 或 so,否则 addr2line 无法解出文件和行号
- asan 也可以静态链接,只需要加 ld flags:
-static-libasan,这样就不需要在运行时加LD_PRELOAD环境变量;如果是 uclibc,可能还需要添加 ld flags:-lasan# main.c 参考 # int main(int argc, char *argv[]) # { # char *a = malloc(10); # free(a); # a[1] = 1; # return 0; # } arm-linux-gnueabihf-gcc -g -fsanitize=address -fno-omit-frame-pointer main.c # 拷贝 /tools/toolchain/gcc-11.1.0-20210608-sigmastar-glibc-x86_64_arm-linux-gnueabihf/arm-linux-gnueabihf/lib/libasan.so.6.0.0 到设备, # 并重命名位 libasan.so.6;在设备上运行上一步编译出来的 a.out LD_PRELOAD=/path/to/libasan.so.6 ./a.out # asan 运行结果如下,需要关注的就是崩溃时的栈的地址 # ==803==ERROR: AddressSanitizer: heap-use-after-free on address 0xb41007b1 at pc 0x00010653 bp 0xbed15c80 sp 0xbed15c84 # WRITE of size 1 at 0xb41007b1 thread T0 # #0 0x10650 (/mnt/a.out+0x10650) # #1 0xb68b6bc4 in __libc_start_main (/lib/libc.so.6+0x17bc4) # 下面的 a.out 需要是没有 strip 过,并且 -g 编译的 arm-linux-gnueabihf-addr2line -e a.out 0x10650 main.c:8
经历以上步骤通常能够抓到踩内存的代码位置,但是为何会踩内存则需要去详细地分析代码
4.2.2 开启 asan 后 oom¶
asan 会占用原本的 2 倍内存(还有 2 倍的 CPU 开销)
- 若开启 asan 后,app 跑了很短时间就 oom 了,此时可能需要缩小 mma 去开启;若还是因为内存不够无法开启 asan,能否试下裁剪掉一些功能;也可以尝试开启 swap
- 若 app 在跑了很长一段时间才出现 oom,可以设置环境变量
ASAN_OPTIONS=quarantine_size_mb=50去限制隔离区的大小(默认是 250MB)
内存不足时,开启 swap 的方法:
- 打开 kernel config:
CONFIG_SWAP,sdk ko 无需重新编译 - 创建 swap 文件(可以在 linux 服务器上执行):
dd if=/dev/zero of=./swap bs=1M count=250 && mkswap ./swap(调整 count 值可以调整 swap 大小),将 swap 文件拷贝到 sd 卡或 emmc - 在设备上开启 swap:
swapon /mnt/sd/swap,确认/proc/meminfo中SwapFree大于 0,证明开启成功;echo 200 > /proc/sys/vm/swappiness调整倾向使用 swap
注意是开启 swap 后还是有可能会内存不足
若客户是 arm64,但是内存不够去开启 asan,可以考虑使用 hwasan(使用的内存仅会增加 30%-50%,且没有隔离区的内存消耗,但功能和 asan 完全一致),和 asan 的使用差别:
-fsanitize=address改为-fsanitize=hwaddress- 拷贝的 libasan.so 改为 libhwasan.so
4.2.3 开启 asan 后无法复现问题¶
若在开启 asan 后复现不到问题,大概率是要对 预编译的库 (.so 或 .a)重新用 asan 编译,比如 sdk 或预编译算法库重新使用 asan 编译
编译带 asan 的 sdk:make DEBUG=256 image -j8
4.2.4 uclibc asan¶
由于 uclibc 默认无法编译出 asan 版本,需要修改 libsanitizer 以适配 uclibc toolchain。
使用方法:将 libasan.a 和 libasan_preinit.o 放到 uclibc toolchain 的目录下 arm-sigmastar-linux-uclibcgnueabihf-9.1.0/arm-sigmastar-linux-uclibcgnueabihf/lib,同时由于是静态链接,不需要在运行时加 LD_PRELOAD 参数了,其他使用方法一致
4.3 kasan (kernel)¶
kernel 踩内存的现象:
- BUGON:原生 kernel code BUGON,或 BUGON 经确认是绝对不可能出现的,可能是 used after free 或内存越界
- 变量变成了不该出现的值(可能不会 panic):大概率是 used after free,也有可能是内存越界
- 读写非法地址,可能会有如下打印:
Unable to handle kernel paging request at virtual addressaddress between user and kernel address ranges- 原因可能是:used after free 或内存越界把指针的值改掉了,或者是使用了未初始化的指针
kasan 开关 CONFIG_KASAN,kernel 和 userspace 不太一样,不能只是单个 ko 去使用 kasan 编译,必须 release 带 kasan 的 sdk,编译命令是 make DEBUG=2 image -j8
开启 kasan 后需要注意的几个问题:
- flash 空间不足:可以开启
CONFIG_KASAN_OUTLINE,生成较小的二进制;默认是CONFIG_KASAN_INLINE=y,其速度比 outline 快 2 倍 - 若出现 oom,请参考 asan 的处理方式
- 通过 gdb 看到文件和行号需要 debug info,即
CONFIG_DEBUG_INFO=y
这里故意写一个 used after free:
MI_S32 MI_SYS_Cmd_ProcShowThreads(/*...*/)
{
char * a = kmalloc(10, GFP_KERNEL);
// ...
kfree(a);
a[0] = 1;
return MI_SUCCESS;
}
kasan log:
BUG: KASAN: use-after-free in MI_SYS_Cmd_ProcShowThreads+0x100/0x110 [mi_sys]
Write of size 1 at addr c3e34600 by task sh/1521
CPU: 0 PID: 1521 Comm: sh Tainted: P O 5.10.117-android12-9-00500-gfdf36a84d0fb-dirty #1
Hardware name: SStar Soc (Flattened Device Tree)
[<c0214440>] (unwind_backtrace) from [<c020dd6c>] (show_stack+0x10/0x14)
[<c020dd6c>] (show_stack) from [<c122bdf8>] (dump_stack_lvl+0x80/0xac)
[<c122bdf8>] (dump_stack_lvl) from [<c04b9380>] (print_address_description+0x5c/0x2ec)
[<c04b9380>] (print_address_description) from [<c04b999c>] (kasan_report+0x16c/0x1a4)
[<c04b999c>] (kasan_report) from [<bf1149bc>] (MI_SYS_Cmd_ProcShowThreads+0x100/0x110 [mi_sys])
[<bf1149bc>] (MI_SYS_Cmd_ProcShowThreads [mi_sys]) from [<bf120260>] (MI_SYS_DEBUG_ProcOnExecCmd+0x80/0x98 [mi_sys])
[<bf120260>] (MI_SYS_DEBUG_ProcOnExecCmd [mi_sys]) from [<bf11af88>] (_MI_SYS_Proc_DevCommonWrite+0x1d8/0x17f8 [mi_sys])
[<bf11af88>] (_MI_SYS_Proc_DevCommonWrite [mi_sys]) from [<c0dda378>] (_CamProcWriteLinux+0x11c/0x180)
[<c0dda378>] (_CamProcWriteLinux) from [<c05b7e8c>] (proc_reg_write+0xc8/0x124)
[<c05b7e8c>] (proc_reg_write) from [<c04ea264>] (vfs_write+0x1c8/0x51c)
[<c04ea264>] (vfs_write) from [<c04ea744>] (ksys_write+0x8c/0xfc)
[<c04ea744>] (ksys_write) from [<c0200140>] (ret_fast_syscall+0x0/0x50)
Exception stack(0xe0057fa8 to 0xe0057ff0)
7fa0: 0000000d a5e02064 00000001 a5e02064 0000000d ffffffff
7fc0: 0000000d a5e02064 00000080 00000004 a6399138 b69b694c 0149b31c b69b6955
7fe0: 00000000 b69b6918 0147fb5d a6379ce0
Allocated by task 1521:
__kasan_kmalloc+0xa0/0xac
MI_SYS_Cmd_ProcShowThreads+0x30/0x110 [mi_sys]
MI_SYS_DEBUG_ProcOnExecCmd+0x80/0x98 [mi_sys]
_MI_SYS_Proc_DevCommonWrite+0x1d8/0x17f8 [mi_sys]
_CamProcWriteLinux+0x11c/0x180
proc_reg_write+0xc8/0x124
vfs_write+0x1c8/0x51c
ksys_write+0x8c/0xfc
ret_fast_syscall+0x0/0x50
0xb69b6918
Freed by task 1521:
kasan_set_track+0x28/0x30
kasan_set_free_info+0x20/0x34
____kasan_slab_free+0xec/0x114
__kasan_slab_free+0x14/0x1c
kfree+0xa8/0x42c
MI_SYS_Cmd_ProcShowThreads+0xf8/0x110 [mi_sys]
MI_SYS_DEBUG_ProcOnExecCmd+0x80/0x98 [mi_sys]
_MI_SYS_Proc_DevCommonWrite+0x1d8/0x17f8 [mi_sys]
_CamProcWriteLinux+0x11c/0x180
proc_reg_write+0xc8/0x124
vfs_write+0x1c8/0x51c
ksys_write+0x8c/0xfc
ret_fast_syscall+0x0/0x50
0xb69b6918
# gdb 根据 BUG 那一行的栈信息去查看代码位置
arm-linux-gnueabihf-gdb interface/src/sys/mi_sys.ko
(gdb) b *(MI_SYS_Cmd_ProcShowThreads+0x100)
Breakpoint 1 at 0x4ab70: file xxxxx.c, line 575.
CONFIG_KASAN_SW_TAGS 对应 user 的 hwasan,只能在 64 位平台上使用,打开后可以减小 kasan 的内存占用
4.4 HW Watchpoints (kernel)¶
若开启 kasan 后无法复现,并且踩的变量一直是同一个,该变量的值很少发生变化,可以考虑使用 HW Watchpoints,因此该方法的使用范围很小
如果需要在 sdk 的 ko 里面加,需要将 kernel/events/hw_breakpoint.c 的 register_wide_hw_breakpoint() gpl 改为 EXPORT_SYMBOL
#include <linux/perf_event.h>
#include <linux/hw_breakpoint.h>
static int len = 0;
static void sample_hbp_handler(struct perf_event *bp, struct perf_sample_data *data, struct pt_regs *regs)
{
pr_info("value is changed\n");
dump_stack();
}
MI_S32 MI_SYS_Cmd_ProcShowThreads(/*...*/)
{
struct perf_event_attr attr;
hw_breakpoint_init(&attr);
attr.bp_type = HW_BREAKPOINT_W | HW_BREAKPOINT_R;
attr.bp_addr = (u32)&len;
attr.bp_len = HW_BREAKPOINT_LEN_4;
register_wide_hw_breakpoint(&attr, sample_hbp_handler, NULL);
len = 1; // 此处对变量的写入会触发中断去调用 sample_hbp_handler
// ...
return MI_SUCCESS;
}
log 显示最后对内存的写入函数是 MI_SYS_Cmd_ProcShowThreads
Exception stack(0xc2461ca8 to 0xc2461cf0)
1ca0: 00000000 2e58b000 401c8642 00000001 c09ea6c8 00000000
1cc0: bf0f3d58 bf0dee34 bf0b4f8c 00000000 00000001 c2461d9c c2461cc0 c2461cf8
1ce0: c01093c0 bf0b502c 60000013 ffffffff
r7:c2461cdc r6:ffffffff r5:60000013 r4:bf0b502c
[<bf0b4f8c>] (MI_SYS_Cmd_ProcShowThreads [mi_sys]) from [<bf0bbac8>] (MI_SYS_DEBUG_ProcOnExecCmd+0x74/0x90 [mi_sys])
r6:c2461e0c r5:c2461da8 r4:00000010
[<bf0bba54>] (MI_SYS_DEBUG_ProcOnExecCmd [mi_sys]) from [<bf0bb0b8>] (_MI_SYS_Proc_DevCommonWrite+0x21c/0x2bc [mi_sys])
r10:c35cbacc r9:00000000 r8:c2461e0c r7:00000000 r6:bf0bba54 r5:bf0f3db8
r4:00000001
[<bf0bae9c>] (_MI_SYS_Proc_DevCommonWrite [mi_sys]) from [<c058367c>] (_CamProcWriteLinux+0xac/0x118)
r10:00000000 r9:c2461f58 r8:0000000d r7:000d2598 r6:c19b2cec r5:c35cbac0
r4:0000000d
[<c05835d0>] (_CamProcWriteLinux) from [<c01e3898>] (proc_reg_write+0x98/0xa8)
r7:000d2598 r6:c1d34500 r5:c05835d0 r4:c1ba0e00
[<c01e3800>] (proc_reg_write) from [<c0167f84>] (vfs_write+0xc0/0x1b0)
r9:c01e3800 r8:000d2598 r7:c09ea6c8 r6:c2461f58 r5:c1d34500 r4:0000000d
[<c0167ec4>] (vfs_write) from [<c01681cc>] (ksys_write+0x78/0xc4)
r9:0000000d r8:c2461f64 r7:c09ea6c8 r6:000d2598 r5:c2461f58 r4:c1d34500
[<c0168154>] (ksys_write) from [<c0168230>] (sys_write+0x18/0x1c)
r9:c2460000 r8:c0008664 r7:00000004 r6:000d2598 r5:b6fce0c0 r4:000c5ea0
[<c0168218>] (sys_write) from [<c0008420>] (ret_fast_syscall+0x0/0x50)
4.5 Dump Kernel Image¶
如果每次 kernel panic 位置不一样,而且经常是 kernel 原生 code 的 panic,可以怀疑是否 ddr 不稳定导致的
通过 dump kernel 的 .text 段可以确认 ddr 是否不稳定:
- 打开 kernel 目录下的 System.map,找到
__start_rodata和_text,得到 .text 段的长度size = __start_rodata - _text cat /proc/iomem获取 .text 段的起始地址,但是 dump 需要 MIU 地址,因此需要减去 System RAM 的起始地址,即addr = kernel-code-start - system-ram-start- 关闭串口(串口输入 11111),打开 tv tool,执行下图的操作
- 导出 vmlinux 的 .text 段:
arm-linux-gnueabihf-objcopy -j .text -O binary vmlinux k_text.bin - 对比从 RAM 导出的文件和 vmlinux 导出的 .text,有许多的小段二进制不同是正常的(static key 造成的),若有一大段出现不同,可以怀疑 ddr 的稳定性
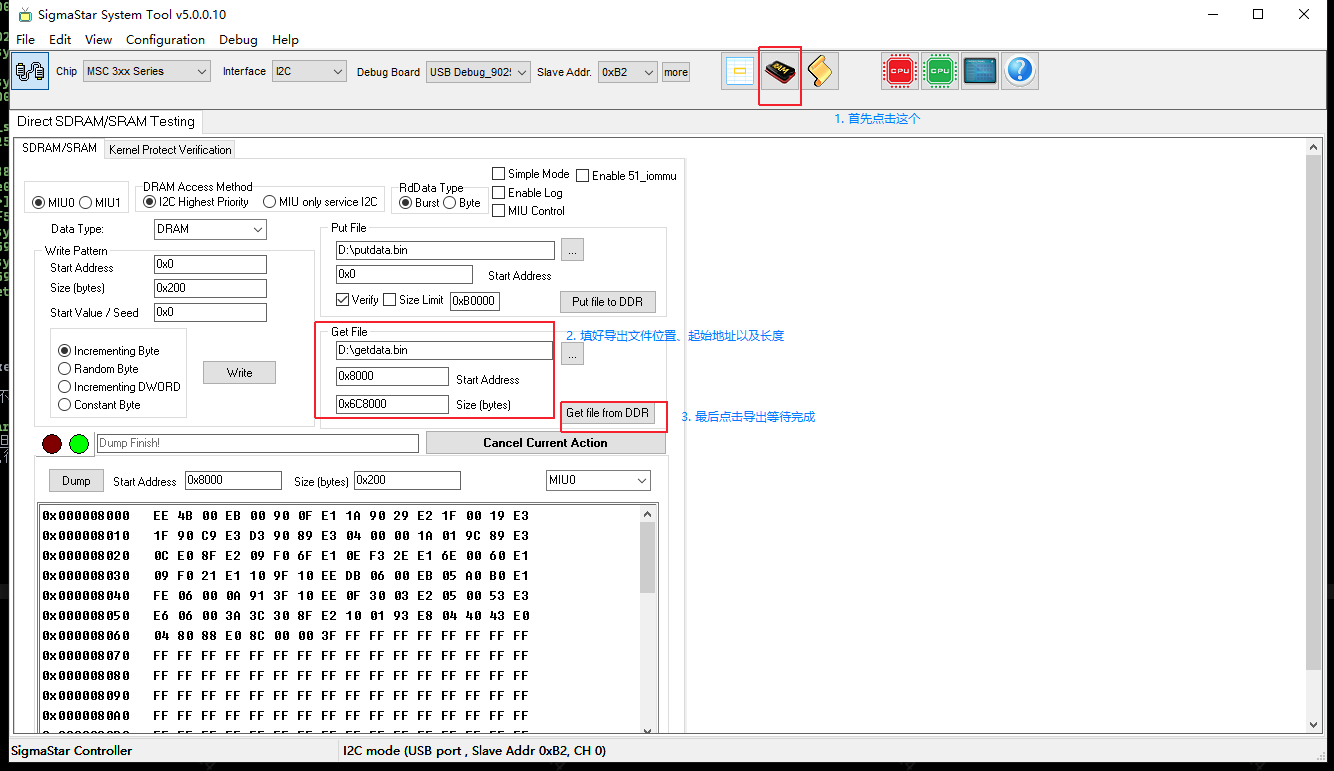
linux kernel 目录下需要执行的 3 个步骤:
# 1. size = 0xc06d0000 - 0xc0008000 = 0x6C8000
cat System.map
c0008000 T _text
...
c06d0000 R __start_rodata
# 2. addr = 0x1000008000 - 0x1000000000 = 0x8000
cat /proc/iomem
...
1000000000-107fffffff : System RAM
1000008000-100097cfff : Kernel code
10009e4000-1000b01d23 : Kernel data
# 3. 导出 vmlinux .text
arm-linux-gnueabihf-objcopy -j .text -O binary vmlinux k_text.bin
5. CPU无异常log卡死问题¶
5.1. dump log_buf¶
当CPU 无异常log卡死时,有可能会有一些重要的log信息没有来得及打印,这时可以通过dump 系统的log buf获取这些log信息。
确定log buf地址有以下几种方法:
-
arm-linux-gnueabihf-sigmastar-9.1.0-gdb vmlinux Reading symbols from vmlinux... (gdb) info address __log_buf Symbol "__log_buf" is static storage at address 0xc041a090.
-
cat System.map |grep __log_buf c041a090 b __log_buf
-
不同chip可能有差别,I6C可以用TV TOOL dump bank 0x1004数据,在offset 0x8和0x9记录了__log_buf地址。
查到__log_buf地址之后,可以使用TV TOOL 或者 Trace32等工具dump对应的内存log信息。
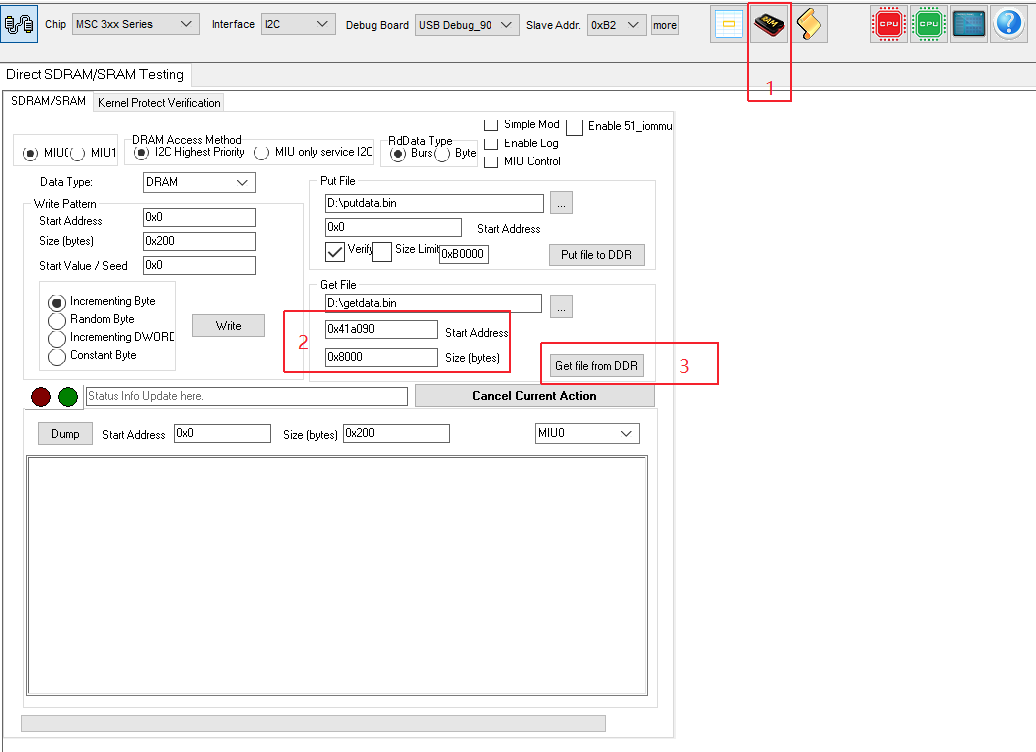
上面查到的log_buf地址是0xc041a090,如果用TV TOOL dump log buf就需要注意一点,就是dump的log_buf地址需要改成0x41a090(减去0xc0000000),dump log buf的长度一般用0x8000。参考下图的步骤1、2、3。
5.2. 接Trace32做debug¶
系统卡死时,可以通过Trace32 debug工具查看系统各线程的信息、CPU寄存器信息以及cache line信息和dram数据等信息。
一般情况下,使用Trace32前的准备如下:
-
EVB board有留出JTAG排插的话可以直接接Trace32。
如果像demo board或者客户板子没有留JTAG排插,可以请硬件owner帮忙。
-
准备好对应chip在Trace32上使用的cmm脚本,可以问SI提供。
-
切换适合Trace32的JTAG mode,具体命令可以问SI提供。
Souffle EVB切换使用的命令是:/customer/riu_w 0x103c 0x60 0x0200
Iford EVB切换使用的命令是:/customer/riu_w 0x103c 0x60 0x80
6. RCU相关问题¶
如果发生RCU stall warning,可以立马怀疑是interrupt戳太多导致(大多数情况是如此)。若 rcu stall 打印的 backtrace 里面有 2 个 gic_handle_irq 基本可以锁定是 interrupt 的问题
所以问题转化为对查明是什么interrupt发生次数过多。
对此可以分为两种情况:
- 串口或者telnet可以操作 多cat /proc/interrupts,从而找出可疑的IRQ
-
无法操作板子 (1)可以使用tv_tool查看main interrupt controller的registers,看是哪个interrupt一直发生
[main interrupt controller registers] Souffle: /customer/riu_r 0x1009 查看fiq offset: 0x4c 0x4d 0x4e 0x4f 查看irq offset: 0x5c 0x5d 0x5e 0x5f Iford: /customer/riu_r 0x1009 查看fiq offset: 0x4c 0x4d 0x4e 0x4f 查看irq offset: 0x5c 0x5d 0x5e 0x5f(2)打开CONFIG_SSTRA_IRQ_DEBUG_TRACE,它会统计每个interrupt发生的次数,然后在发生soft lockup时打印出统计信息