AI Glasses eMMC选型关键参数量测参考¶
REVISION HISTORY¶
| Revision No. | Description |
Date |
|---|---|---|
| 1.0 | 09/03/2025 |
1. 概述¶
在AI眼镜设计中,eMMC(嵌入式多媒体存储卡)的选型需在极端紧凑的空间内兼顾高性能、低功耗、大容量及高可靠性。本文档结合AI眼镜应用场景,给出选型关键要素 并且重点阐述性能与功耗指标的量测方案。
2. 核心选型维度¶
2.1. 容量需求¶
2.1.1. 入门级(基础AI交互)¶
32GB是当前主流起点,可满足基础操作系统、语音助手、基础应用和少量媒体存储(如Meta Ray-Ban、雷鸟V3)
2.1.2. 中高端(多模态AI/本地模型)¶
需要64GB或更高的容量,支撑本地AI模型缓存、高清视频录制、离线地图等(如支持4K录像的眼镜需大于64GB)
2.1.3. 未来趋势¶
128GB方案已经出现(如江波龙7.2平方毫米 eMMC),为端侧大模型预留空间
2.2. 物理尺寸与封装¶
2.2.1. 厚度¶
必须小于等于0.8毫米(行业硬性要求),高端产品趋向0.6毫米(如江波龙ePOP4x)
2.2.2. 面积¶
标准型eMMC(11.5x13 毫米)已不满足要求,选型目标:
超小型:7.2x7.2毫米(江波龙)或9x7.5毫米(XREAL方案)
堆叠集成:ePOP(贴装SoC上方)或eMCP(集成LPDDR),节省60% PCB面积(如佰维 BWCK1EZH-32G-X用于Ray-Ban Meta)
2.3. 性能与接口¶
接口协议:eMMC 5.1为底线(带宽大于等于400MB/s),支持HS400模式保障流畅AI数据流
读写速度:顺序读大于等于250MB/s、顺序写大于等于180MB/s(如佰维SP1800主控实测读327MB/s/写297MB/s)
随机性能:4K随机读大于等于5000 IOPS,随机写大于等于3000 IOPS(影响多任务响应)
2.4. 功耗优化¶
休眠功耗:小于等于1mW
动态功耗:支持智能休眠+动态调频(如江波龙)
供电电压:优选1.8V/3.3V双电压设计,适应不同供电场景
2.5. 可靠性与耐久性¶
温度范围:工业级标准(-25摄氏度至85摄氏度),保障户外或特殊场景使用
纠错能力:必须支持LDPC纠错(江波龙/佰维等方案均具备)
写入寿命:大于等于 P/E cycles(需自研固件优化,如佰维FW算法)
主流供应商及产品对比
| 厂商 | 代表产品 | 核心优势 | 应用场景 |
| 江波龙 | 7.2x7.2mm eMMC | 最小尺寸(减65%面积),0.8mm厚,LDCP纠错 | 超轻薄眼镜 |
| 金士顿 | 8x9.5mm eMMC | 超小尺寸,平衡功耗与性能 | 紧凑型AI设备 |
| 佰维 | ePOP(8.0x9.5x0.7mm) | 集成LPDDR,节省PCB | 高性能AI交互 |
| 三星 | eMMC Pro | 高耐久性,高速接口 | 工业/军用级 |
| 恺侠 | eMMC Enterprise | 低延迟,温度适应性佳 | 高温环境应用 |
3. 性能测试方法¶
3.1. 测试准备¶
本文档给出在Linux eMMC boot环境下,对eMMC卡进行性能测试的方案:
3.1.1. 测试分区¶
由于是eMMC boot启动,为了避免损坏正常分区的数据,需要创建新的分区进行测试
新建分区方法:
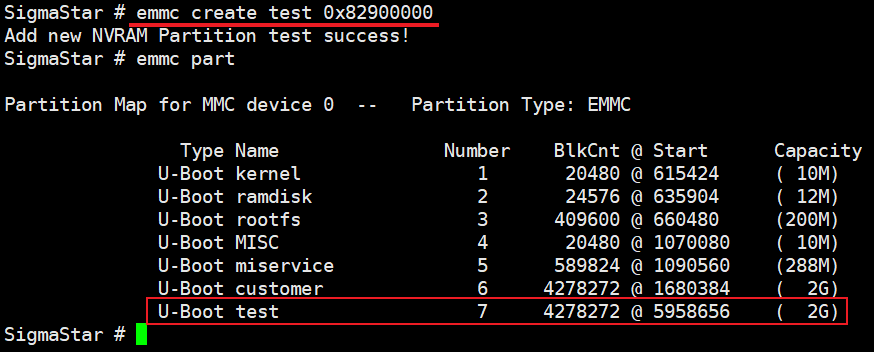
在uboot下使用{emmc create name size}命令创建测试分区即可,例如:
emmc create test 0x82900000 // 创建一个大小为2GB,名称为test的测试分区
创建成功后,可以执行{emmc part}命令查看新建的分区,如下图所示
3.1.2. FIO工具使用简介¶
| 参数 | 解释说明 |
| filename=/dev/mmcblk0p7 | 测试设备或文件名称(填绝对路径) |
| direct=1 | 使用directIO,测试过程绕过系统自带的缓存 |
| rw=randread | 测试I/O随机读能力 |
| rw=randwrite | 测试I/O随机写能力 |
| rw=read | 测试I/O顺序读能力 |
| rw=write | 测试I/O顺序写能力 |
| bs=512 | 单次IO的块文件大小为512字节 |
| size=1G | 每个线程读写的数据量为1GB |
| name=mytest | 当前指令任务的名字 |
| thread | 使用pthread_create创建线程方式并发执行 |
| ioengine=psync | 指定IO引擎使用psync方式 |
| numjobs=4 | 测试的线程数是4 |
| group_reporting | 显示任务的测试结果 |
顺序写:
测试单次写的块IO大小为512字节,数据大小为1G
fio -filename=/dev/mmcblk0p7 -direct=1 -thread -rw=write -ioengine=psync -bs=512 -size=1G -numjobs=4 -group_reporting -name=mytest
测试单次写的块IO大小为1M,数据大小为1G
fio -filename=/dev/mmcblk0p7 -direct=1 -thread -rw=write -ioengine=psync -bs=1M -size=1G -numjobs=4 -group_reporting -name=mytest
顺序读:
测试单次读的块IO大小为512字节,数据大小为1G
fio -filename=/dev/mmcblk0p7 -direct=1 -thread -rw=read -ioengine=psync -bs=512 -size=1G -numjobs=4 -group_reporting -name=mytest
测试单次读的块IO大小为1M,数据大小为1G
fio -filename=/dev/mmcblk0p7 -direct=1 -thread -rw=read -ioengine=psync -bs=1M -size=1G -numjobs=4 -group_reporting -name=mytest
随机写:
测试单次写的块IO大小为512字节,数据大小为1G
fio -filename=/dev/mmcblk0p7 -direct=1 -thread -rw=randwrite -ioengine=psync -bs=512 -size=1G -numjobs=4 -group_reporting -name=mytest
测试单次写的块IO大小为1M,数据大小为1G
fio -filename=/dev/mmcblk0p7 -direct=1 -thread -rw=randwrite -ioengine=psync -bs=1M -size=1G -numjobs=4 -group_reporting -name=mytest
随机读:
测试单次读的块IO大小为512字节,数据大小为1G
fio -filename=/dev/mmcblk0p7 -direct=1 -thread -rw=randread -ioengine=psync -bs=512 -size=1G -numjobs=4 -group_reporting -name=mytest
测试单次读的块IO大小为1M,数据大小为1G
fio -filename=/dev/mmcblk0p7 -direct=1 -thread -rw=randread -ioengine=psync -bs=1M -size=1G -numjobs=4 -group_reporting -name=mytest
3.2. 测试结果¶
3.2.1 FIO 报告分析¶
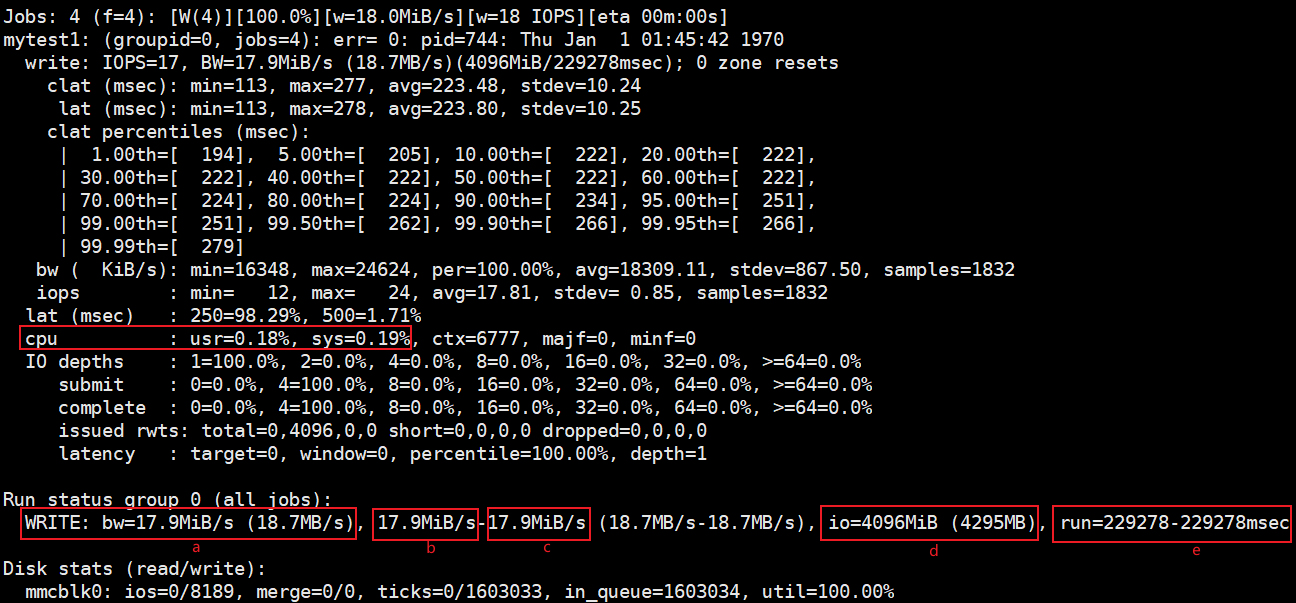
主要关注红色方框内的几个参数
cpu: 用户(usr)时间和系统(sys)时间的占比
bw: 总带宽(a),最小带宽(b)和最大带宽©,这里均为17.9MiB/S(括号内是10的幂的形式)
io: 所有线程执行的累计I/O大小(d),四个线程累计写4096MiB(括号内是10的幂的形式)
run: 线程中最小和最长的运行时间(e),这里运行时间为229.278秒
3.2.2 性能测试结果统计¶
CPU规格:arm, cortex-a32 x2
CPU主频:800MHz
DDR型号:lpddr4x
eMMC模式:high speed sdr mode, clk frequency 48MHz
-
江波龙FEM6NNO64G-A3N14
测试项 IOPS BW SIZE BLOCKSIZE 顺序写 1230 630KB/s 1GB 512Byte 顺序写 17 18.7MB/s 1GB 1MB 顺序读 6724 3443KB/s 1GB 512Byte 顺序读 19 20.3MB/s 1GB 1MB 随机写 2316 1187KB/s 1GB 512Byte 随机写 17 18.6MB/s 1GB 1MB 随机读 5617 2876KB/s 1GB 512Byte 随机读 19 20.2MB/s 1GB 1MB -
时创意E64GCM7TIABESD
测试项 IOPS BW SIZE BLOCKSIZE 顺序写 1230 630KB/s 1GB 512Byte 顺序写 17 18.7MB/s 1GB 1MB 顺序读 6724 3443KB/s 1GB 512Byte 顺序读 19 20.3MB/s 1GB 1MB 随机写 2316 1187KB/s 1GB 512Byte 随机写 17 18.6MB/s 1GB 1MB 随机读 5617 2876KB/s 1GB 512Byte 随机读 19 20.2MB/s 1GB 1MB -
金士顿EMMC32G-KC30
测试项 IOPS BW SIZE BLOCKSIZE 顺序写 3994 2045KB/s 1GB 512Byte 顺序写 17 18.5MB/s 1GB 1MB 顺序读 5295 2711KB/s 1GB 512Byte 顺序读 19 20.3MB/s 1GB 1MB 随机写 1997 1023KB/s 1GB 512Byte 随机写 17 18.3MB/s 1GB 1MB 随机读 3539 1807KB/s 1GB 512Byte 随机读 18 19.7MB/s 1GB 1MB -
金士顿EMMC64G-TB9F
测试项 IOPS BW SIZE BLOCKSIZE 顺序写 5046 2584KB/s 1GB 512Byte 顺序写 17 18.6MB/s 1GB 1MB 顺序读 6741 3451KB/s 1GB 512Byte 顺序读 19 20.1MB/s 1GB 1MB 随机写 3053 1563KB/s 1GB 512Byte 随机写 17 18.5MB/s 1GB 1MB 随机读 4926 2522KB/s 1GB 512Byte 随机读 19 20.1MB/s 1GB 1MB
4. STR时长关键测试点¶
4.1 ROM阶段耗时¶
4.1.1 eMMC量测点¶
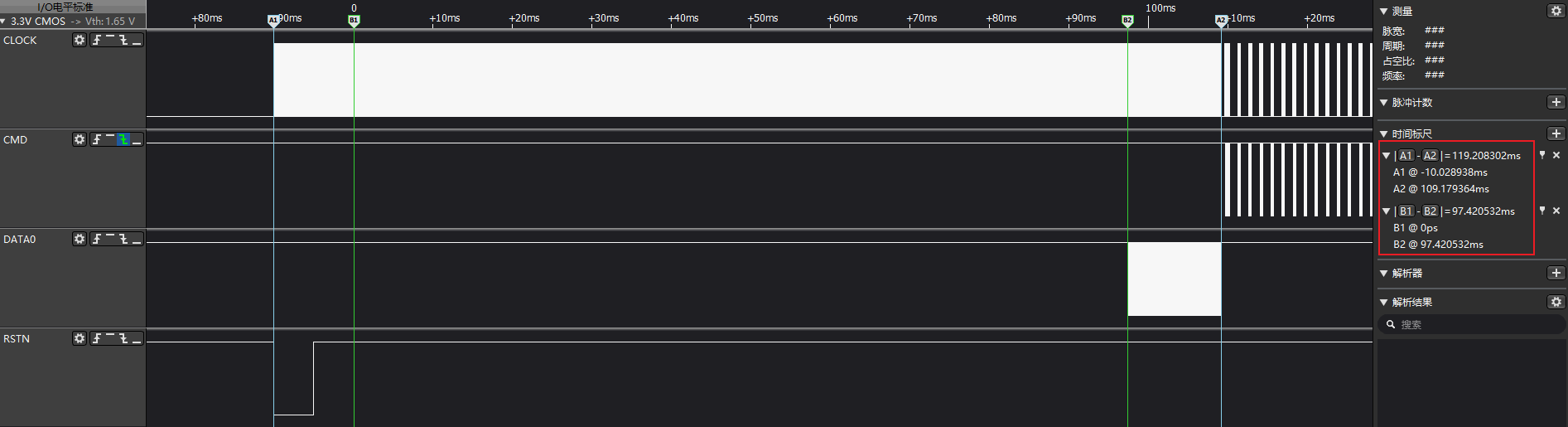
如上图所示,rom阶段,在eMMC执行cmd0(arg:0xfffffffa)进入boot mode加载镜像前,会先执行hw reset操作,即rstn pin会拉低拉高操作。
以hw reset为起始,并以cmd0(arg:0x00000000)结束退出boot mode为止,这一段即是eMMC在rom阶段的主要耗时。
A1-B1阶段:hw reset周期,固定10ms
B1-B2阶段: cmd0(arg:0xfffffffa)发出到eMMC卡开始发送镜像数据等待周期(cmd0 start read)
B2-A2阶段: eMMC卡开始发送镜像数据到cmd0(arg:0x00000000)周期(cmd0 read finish),频率使用12MHz,每种型号耗时固定
4.1.2 eMMC SPEC定义boot mode耗时¶

如上图所示,eMMC协议手册规定,cmd0(arg:0xfffffffa)发出到eMMC卡开始发送镜像数据等待周期,最大允许是50ms。
4.2 IPL阶段耗时¶
IPL resume阶段,主要是为调整TF-A做准备操作,主要耗时点是从eMMC设备加载env和ott信息产生的。
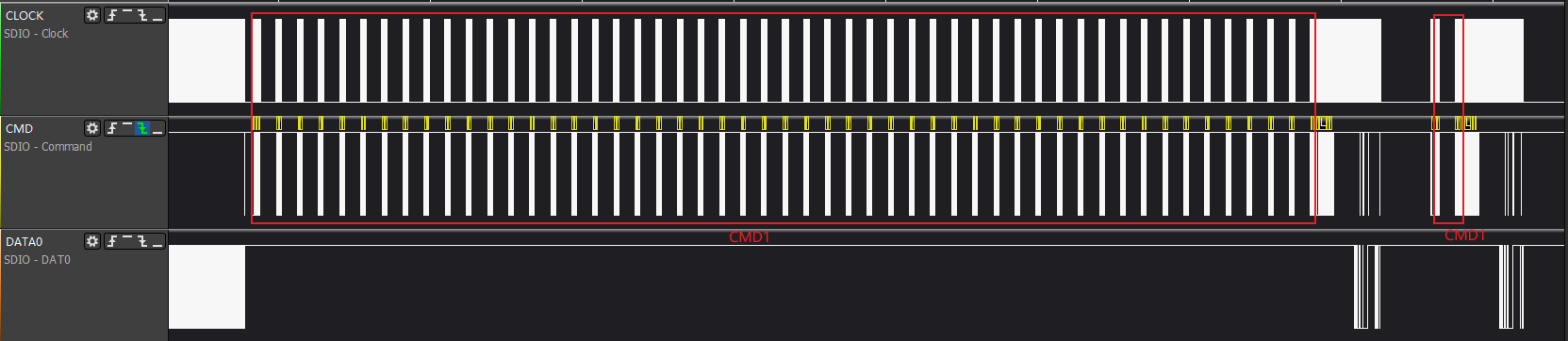
如上图,在执行从eMMC设备加载数据时,会先进行初始化操作,其中cmd1会一直轮询,直到eMMC设备准备好后才会往下执行,该部分耗时比较大。
4.2.1 IPL量测点¶
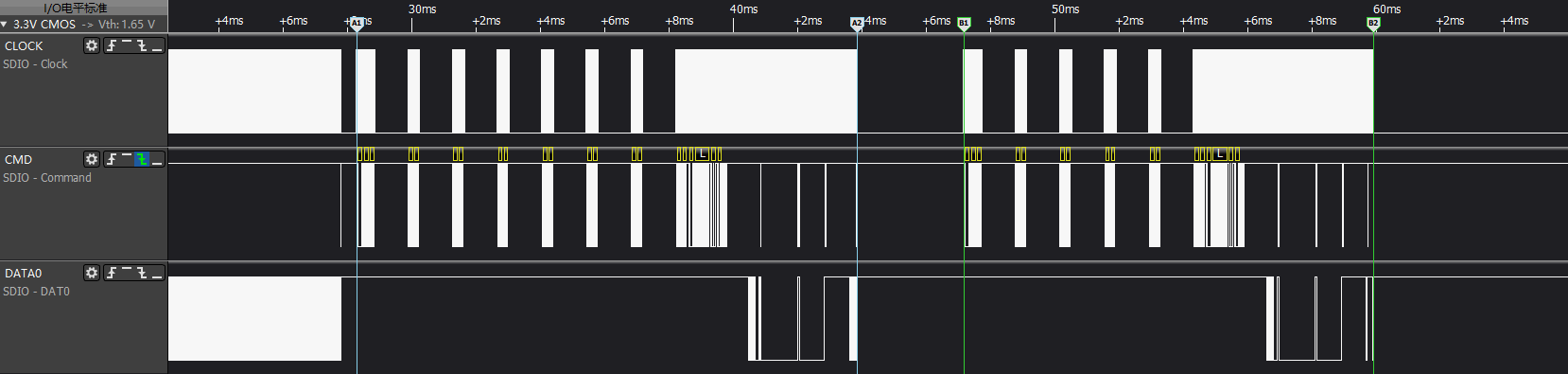
A1-A2阶段:load env周期,从eMMC init操作到env数据加载完成为止,即从cmd0(arg:0x00000000)到cmd18 + cmd12结束
B1-B2阶段: load miu ott周期,从eMMC init操作到env数据加载完成为止,即从cmd0(arg:0x00000000)到cmd17结束
4.3 Kernel阶段耗时¶
kernel阶段,系统执行resume过程,主要耗时点是各个模块resume接口的耗时。eMMC实际是执行runtime PM的恢复操作,如果在resume阶段 并没有访问eMMC的操作,则不会有额外耗时。其耗时点在真正访问eMMC设备时执行runtime resume操作产生。
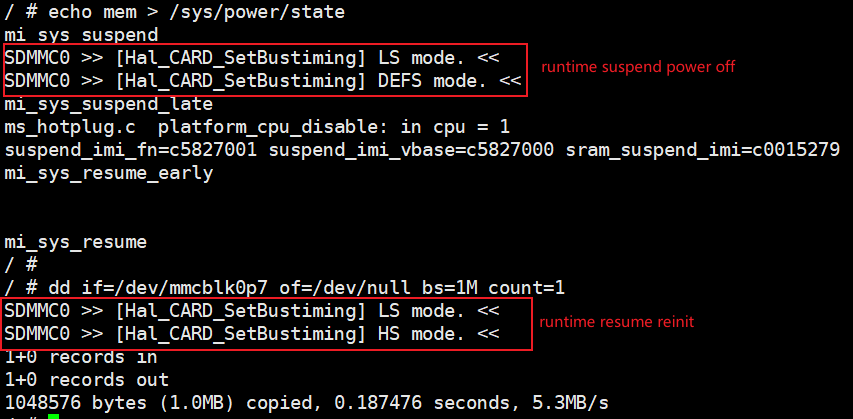
如上图所示,在系统suspend阶段,eMMC会进入suspend状态,并且在真正使用时,才执行resume操作。因此resume阶段的耗时,会延迟到第一次使用时进行。
4.3.1 Kernel量测点¶
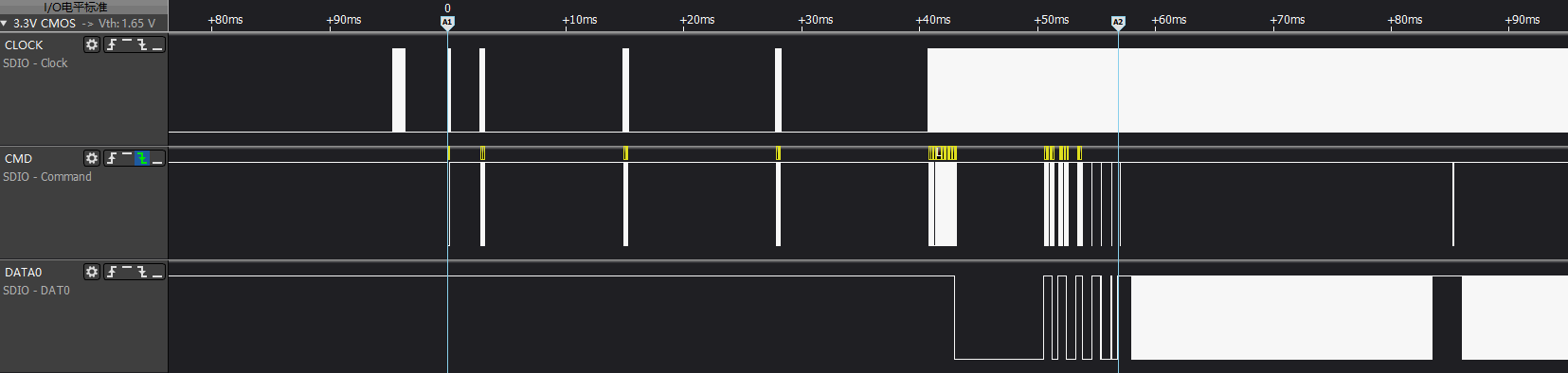
A1-A2阶段:eMMC runtime resume阶段的reinit周期,即从cmd0(arg:0x00000000)到最后一组switch命令cmd6 + cmd13结束
4.4 eMMC在resume阶段耗时统计¶
注意:文档以不掉电str为例,列举不同eMMC型号在resume过程各个阶段的耗时数据,其他eMMC型号按文档给出的测试点进行量测即可。
| eMMC型号 | ROM | IPL | KERNEL | |||||
| hw reset | cmd0 start read | cmd0 read finish | rom total cost | load env | load ott | ipl total cost | kernel reinit | |
| 金士顿EMMC64G-TB9F | 10ms | 96.6ms | 11.7ms | 118.3ms | 74.3ms | 6ms | 80.3ms | 96.5ms |
| 金士顿EMMC32G-KC30 | 10ms | 4ms | 11.7ms | 25.7ms | 9.5ms | 11.9ms | 21.4ms | 39ms |
| 江波龙FEM6NNO64G-A3N14 | 10ms | 42.2ms | 11.7ms | 63.9ms | 8.5ms | 5.4ms | 13.9ms | 81.8ms |
| 时创意E64GCM7TIABESD | 10ms | 16ms | 11.7ms | 37.7ms | 15.5ms | 12.7ms | 28.2ms | 54.6ms |