YOLO-World
1 Overview¶
1.1 Background Introduction¶
YOLO-World is an innovative real-time open vocabulary object detection method that allows detectors to understand and recognize new object categories that did not appear in the training data through the introduction of vision-language modeling techniques.
Yolov8-world incorporates this real-time open vocabulary object detection method, enabling the detection of any object in images based on descriptive text. Yolov8-world significantly reduces computational requirements while maintaining highly competitive performance. Yolov8-world provides several different model sizes: s, m, l, and the accuracies of these open-source models are as follows:
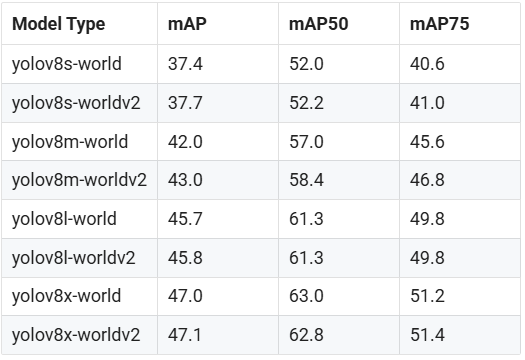
For more details, please refer to the official YOLOv8-world documentation
https://docs.ultralytics.com/models/yolo-world/#available-models-supported-tasks-and-operating-modes
The source code is as follows:
https://github.com/ultralytics/ultralytics/blob/v8.2.32/ultralytics/engine/exporter.py
The YOLOv8 open-source model download link is as follows:
1.2 Usage Instructions¶
The Linux SDK-alkaid comes with pre-converted offline models and board-side examples by default. The relevant file paths are as follows:
- Board-side example program path Linux_SDK/sdk/verify/opendla/source/vlm/yolo_world
- Board-side offline model paths Linux_SDK/project/board/{chip}/dla_file/ipu_open_models/vlm/yolov8s_world_image_encode.img Linux_SDK/project/board//dla_file/ipu_open_models/vlm/yolov8s_world_text_encode.img
- Board-side test image path Linux_SDK/sdk/verify/opendla/source/resource/bus.png
If the user does not need to convert the model, they can jump directly to section 3.
2 Model Conversion¶
2.1 ONNX Model Conversion¶
-
Setting up the Python environment
$conda create -n yolov8 python==3.10 $conda activate yolov8 $git clone https://github.com/ultralytics/ultralytics $cd ultralytics $pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simpleNote: The provided Python environment setup is only a reference example; for the specific setup process, please refer to the official source running tutorial:
https://docs.ultralytics.com/quickstart/ -
Model Testing
- Create a yolov8-world directory and write the model testing script
predict.pyfrom ultralytics import YOLOWorld # Initialize a YOLO-World model model = YOLOWorld("./yolov8-world/yolov8s-world.pt") # or select yolov8m/l-world.pt for different sizes # Execute inference with the YOLOv8s-world model on the specified image results = model.predict("path/to/image.jpg") # Show results results[0].show() - Run the model testing script to ensure the yolov8 environment is configured correctly. $python ./yolov8-world/predict.py
For specific details, please refer to the official yolov8 testing documentation
https://docs.ultralytics.com/zh/models/yolo-world/#predict-usage - Create a yolov8-world directory and write the model testing script
-
Model Export
-
Modify the model script
- Insert at line 233 of exporter.py text = torch.randn((1,1,512),dtype=float).to(self.device)
- Insert at line 268 of exporter.py self.text = text
-
Modify lines 409~419 of exporter.py
-
Original code
torch.onnx.export( self.model.cpu() if dynamic else self.model, # dynamic=True only compatible with cpu self.im.cpu() if dynamic else self.im, f, verbose=False, opset_version=opset_version, do_constant_folding=True, # WARNING: DNN inference with torch>=1.12 may require do_constant_folding=False input_names=["images"], output_names=output_names, dynamic_axes=dynamic or None, ) -
Modify code
torch.onnx.export( self.model.cpu() if dynamic else self.model, # dynamic=True only compatible with cpu (self.im.cpu(),False,False,self.text) if dynamic else (self.im,False,False,self.text), f, verbose=False, opset_version=opset_version, do_constant_folding=True, input_names=["images", "profile", "visualize", "text_feats"], output_names=output_names, dynamic_axes=dynamic or None, )
-
-
Write the model conversion script
export.py:import os import sys sys.path.append(os.getcwd()) from typing import Union, List, Tuple from ultralytics import YOLOWorld import clip import torch.nn as nn import torch import onnx import onnxruntime import onnxsim device = torch.device("cuda" if torch.cuda.is_available() else "cpu") class TextModelWrapper(nn.Module): def __init__(self, clip_model_name: str, device: torch.device = "cuda" if torch.cuda.is_available() else "cpu", ): super().__init__() # check model info self.clip_model_name = clip_model_name self.device = device # load CLIP self.model = clip.load(clip_model_name)[0] self.model.float() self.model.eval() # load tokenize def forward(self, tokens): tokens = tokens.to(self.device).to(torch.int32) text_features = self.model.encode_text(tokens).float() text_features = text_features.mean(axis=0, keepdim=True) text_features_norm = text_features / text_features.norm(dim=-1, keepdim=True) return text_features_norm clip_text = TextModelWrapper("./yolov8-world/ViT-B-32.pt", device= device) text='person' text_token = clip.tokenize(text).to('cpu') text_token = text_token.split(80)[0].split(80)[0] f='./yolov8-world/clip_text_encode.onnx' with torch.no_grad(): torch.onnx.export( clip_text, text_token, f, opset_version=13, input_names=['text'], output_names=['text_feats'], do_constant_folding=False) model_onnx = onnx.load(f) model_onnx, check = onnxsim.simplify(model_onnx) onnx.save(model_onnx, f) model = YOLOWorld("./yolov8-world/yolov8s-worldv2.pt") # load a pretrained model (recommended for training) model.set_classes(["person"]) path = model.export(format="onnx",imgsz=[640, 640], simplify=True, opset=13) # export the model to ONNX format -
Running the model conversion script will generate clip_text_encode.onnx and yolov8s-worldv2.onnx models in the
yolov8-worlddirectory $python ./yolov8-world/export.py
-
2.2 Offline Model Conversion¶
2.2.1 Preprocessing & Postprocessing Instructions¶
-
Preprocessing
The input information for the successfully converted yolov8s-worldv2.onnx model is shown in the figure below. This model has two inputs: image input and text embedding input. The dimensions of the image input are (1, 3, 640, 640), and the dimensions of the text embedding input are (1, 1, 512). Additionally, the image input must normalize pixel values to the range [0, 1].

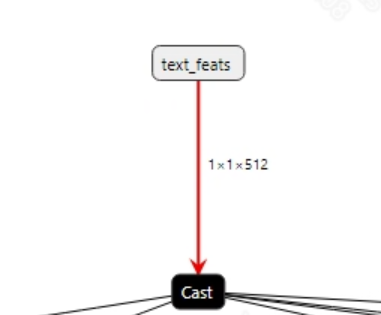
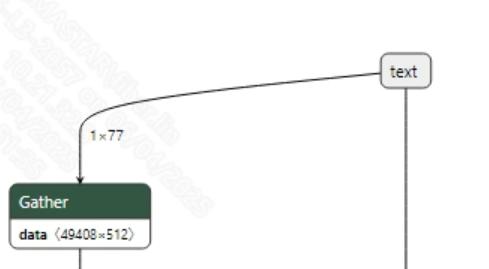
-
Postprocessing
The output information of the yolov8s-worldv2.onnx and clip_text_encode.onnx models is shown in the figure below. The output dimensions for the image model are (1, 5, 8400) and (1, 1, 512), while the output dimension for the text model is (1, 512). The output from the text model will serve as the input to the image model; in the output dimensions of the image model, 8400 is the number of candidate boxes, and 5 represents 4 bounding box coordinates and 1 class probability. After obtaining the candidate boxes from the model output, all the candidate box classes must be judged, and NMS (Non-Maximum Suppression) must be performed to output correct coordinate boxes. (If more categories are to be detected, the number of input categories must be increased during the ONNX model conversion.)
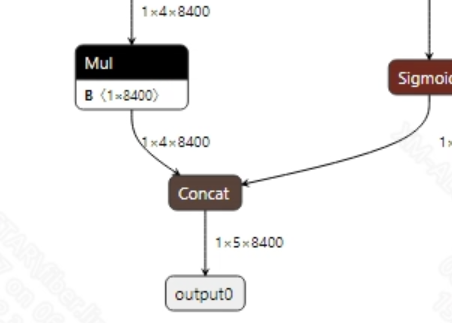
2.2.2 Offline Model Conversion Process¶
Note: 1) OpenDLAModel corresponds to the smodel file extracted from the compressed package image-dev_model_convert.tar. 2) The conversion command must be run in a Docker environment; please load the SGS Docker environment according to the Docker development environment tutorial.
- Copy the ONNX model to the conversion code directory $cp ./yolov8-world/yolov8s-worldv2.onnx OpenDLAModel/vlm/yolov8-wolrd/onnx $cp ./yolov8-world/clip_text_encode.onnx OpenDLAModel/vlm/yolov8-wolrd/onnx
- Conversion command $cd IPU_SDK_Release/docker $bash run_docker.sh # Enter the OpenDLAModel directory in the Docker environment $cd /work/SGS_XXX/OpenDLAModel $bash convert.sh -a vlm/yolov8_world -c config/vlm_yoloworld.cfg -p SGS_IPU_Toolchain (absolute path) -s false
- Final generated model locations output/{chip}_/yolov8_world_image_encode.img output/{chip}_/yolov8_world_image_encode_fixed.sim output/{chip}_/yolov8_world_image_encode_float.sim output/{chip}_/yolov8_world_text_encode.img output/{chip}_/yolov8_world_text_encode_fixed.sim output/{chip}_/yolov8_world_text_encode_float.sim
2.2.3 Key Script Parameter Analysis¶
- input_config_img.ini
[INPUT_CONFIG]
inputs = images,text_feats; # ONNX input node names, separated by commas if there are multiple;
training_input_formats = RGB,RAWDATA_F32_NHWC; # Input format during model training, usually RGB;
input_formats = YUV_NV12,RAWDATA_F32_NHWC; # Board-side input formats, can choose BGRA or YUV_NV12 based on the situation;
quantizations = TRUE,TRUE; # Enable input quantization, do not modify;
mean_red = 0; # Mean, related to model preprocessing, configure according to actual conditions;
mean_green = 0; # Mean, related to model preprocessing, configure according to actual conditions;
mean_blue = 0; # Mean, related to model preprocessing, configure according to actual conditions;
std_value = 255; # Variance, related to model preprocessing, configure according to actual conditions;
[OUTPUT_CONFIG]
outputs = output0; # ONNX output node names, separated by commas if there are multiple;
dequantizations = TRUE; # Whether to enable dequantization, fill according to actual needs, recommended to be TRUE. If set to False, output will be int16; if set to True, output will be float32.
[OPTIMIZE_CONFIG]
Light_Offline_Model=TRUE;
- input_config_text.ini
[INPUT_CONFIG]
inputs = text; # ONNX input node names, separated by commas if there are multiple;
input_formats = RAWDATA_U16_NHWC; # Board-side input format, can choose BGRA or YUV_NV12 based on the situation;
quantizations = TRUE; # Enable input quantization, do not modify;
[OUTPUT_CONFIG]
outputs = test_feats; # ONNX output node names, separated by commas if there are multiple;
dequantizations = TRUE; # Whether to enable dequantization, fill according to actual needs, recommended to be TRUE. If set to False, output will be int16; if set to True, output will be float32.
[OPTIMIZE_CONFIG]
optimize_layernorm_precision=TRUE; # Operator optimization
optimize_Instancenorm_precision=TRUE; # Operator optimization
- vlm_yolov8_world.cfg
[YOLOWORLD]
CHIP_LIST=pcupid # Platform name, must match the board platform; otherwise, the model cannot run
Model_LIST=yolov8s-worldv2.onnx,clip_text_encode # Input ONNX model names
INPUT_SIZE_LIST=0,0 # Model input resolution
INPUT_INI_LIST=input_config_img.ini,input_config_text.ini # Configuration files
CLASS_NUM_LIST=0,0 # Just fill in 0
SAVE_NAME_LIST=yolov8_world_image_encode.img,yolov8_world_text_encode.img # Output model names
QUANT_DATA_PATH=images_list.txt,quant_data_txt # Path for quantization images
2.3 Model Simulation¶
- Obtain float/fixed/offline model outputs
$bash convert.sh -a vlm/yolov8_world -c config/vlm_yoloworld.cfg -p SGS_IPU_Toolchain (absolute path) -s true
After executing the above command, the output tensor of the
floatmodel will be saved by default in a txt file under the pathvlm/yolov8_world/log/output. In addition, thevlm/yolov8_world/convert.shscript also provides simulation examples forfixedandoffline, allowing users to obtain outputs for thefixedandofflinemodels by uncommenting code blocks during execution. - Model Accuracy Comparison
With the input being the same as the aforementioned models, enter the environment built in section 2.1, and add the following print statement at line 249 in the
ultralytics/nn/modules/head.pyfile: print(y) The accuracy verification for the text model can refer to theCLIPalgorithm. This will obtain the output tensor for the corresponding node in the PyTorch model, allowing for comparison with the float, fixed, and offline models. It should also be noted that the original model's output format isNCHW, while the output formats of the float/fixed/offline models areNHWC.
3 Board-side Deployment¶
3.1 Program Compilation¶
Before compiling the example program, it is necessary to select the appropriate deconfig based on the board (nand/nor/emmc, ddr model, etc.) for the complete SDK compilation. For details, refer to the alkaid SDK sigdoc document "Development Environment Setup." - Compile the board-side yolov8_world example. $cd sdk/verify/opendla make clean && make source/vlm/yolov8_world -j8 - Final generated executable file location sdk/verify/opendla/out//app/prog_vlm_yolov8_world
3.2 Running Files¶
When running the program, you need to copy the following files to the board: - prog_vlm_yolov8_world - bus.png - yolov8_world_image_encode.img - yolov8_world_text_encode.img
3.3 Running Instructions¶
-
Usage:
./prog_vlm_yolov8_world image text imgModel textModel dict(command to run the executable) -
Required Input:
- image: path to the image folder/single image
- text: text description such as “person”, "cars". Since the model conversion is set to single class only, multi-class descriptions such as “person, cars” cannot be used.
- imgModel: path to the offline model to be tested
- textModel: path to the offline model to be tested
- dict: dictionary
-
Typical output:
./prog_vlm_yolo_world resource/bus.jpg "person" models/yolov8_world_image_encode.img models/yolov8_world_text_encode.img resource/en_vocab.txt client [745] connected, module:ipu text/img model input nums: 1, 2 found 1 images! text model invoke time: 25.727000 ms [0] processing resource/bus.jpg... fillbuffer processing... net input width: 640, net input height: 640 img model invoke time: 101.744000 ms postprocess time: 0.878000 ms outImagePath: ./output/705695/bus.png ------shutdown IPU0------ client [745] disconnected, module:ipu
