7. IPU Toolchain Operator Support
1. Caffe Supported Operators¶
| Operator | Remarks |
|---|---|
| ArgMax | only support top 1 |
| Axpy | |
| BatchNorm | |
| Concat | maximum 1024 tensor concat |
| Convolution | Constraints: All tensor size < 2^31 If kernel size is do*h*w*di then h * w < 64 when group is 1: convert to Depthwise Convolution; when group is C: convert to Convolution; when group is (1, C): break into GroupConv round(di/16)*round(do/16) < 512 * 1024 |
| ConvolutionDepthwise | natively supports Kernel_size of 3*3, 6*6, 9*9, other cases convert to Convolution with limit constraints: Pad range: [0, 1] |
| CReLU | input <= 4 dimensions |
| ContinuationIndicator | |
| Crop | |
| Deconvolution | All tensor size < 2^31 If kernel size is do*h*w*di, h * w < 64 round(di/16)*round(do/16) < 512 * 1024 |
| Dropout | |
| Eltwise | For PROD and SUM, for two input tensors, when they are 4D vectors, meet the following conditions 1. NCHW, const 2. NCHW, C dimensional vector 3. NCHW, NCHW When they are 5D vectors, meet 1. NCDHW, const 2. NCDHW, NCDHW |
| Flatten | |
| InnerProduct | If weight size do*di round(di/16)*round(do/16) < 512 * 1024 |
| Permute | |
| Pooling | If kernel size is h*w 1. AVGPooling (1).FilterW <= 255, FilterH <= 255, (2).AvePooling_U8: FilterMax(FilterW*FilterH) = 12288, (3).AvePooling_S16: FilterMax(FilterW*FilterH) = 12288 2. MaxPooling: FilterW <= 255, and FilterMax(FilterW*FilterH) = 6029312 |
| PriorBox | |
| Power | only supports positive integer exponent |
| Reshape | |
| Reverse | |
| ROIPooling | The rois input dimension of ROIPooling is (N×5). When the following network is all InnerProduct, N can be set to greater than 1. If there is any convolution in the following network, N can only be set to 1, and the second network needs to be executed N times. For usage method and constraints, see Please Note below. |
| ReLU | input <= 4 dimensions |
| PRuLU | input <= 4 dimensions |
| Sigmoid | |
| Slice | |
| Scale | For two input tensors, the shape meets the following conditions 1. 4D vector, NCHW 2. NCHW, const 3. NCHW, C dimensional vector 4. NCHW, NCHW When it is a 5D vector, meet 1. NCDHW, const 2. NCDHW, NCDHW |
| Softmax | If you need to compute on a specific dimension, the dimension to be calculated should be transposed to the last dimension (the innermost dimension), maximum support 32*512=16384 |
| Splite | |
| ShuffleChannel | |
| Tanh | input <= 4 dimensions |
| Threshold | only supports 4D input |
| Tile | |
| Upsample | The Upsample operator does not exist in Caffe, you can manually modify Deconvolution to Upsample only supports 4D input Only support same scale on H and W |
| Reorg | only supports stride = 2 |
| LSTM | supports unidirectional and bidirectional |
Please Note:
-
The Upsample operator is described in the prototxt as follows:
layer { bottom: "layer85-conv" top: "layer86-upsample" name: "layer86-upsample" type: "Upsample" upsample_param { scale: 2 } }
The scale parameter is equivalent to the Stride of the Deconvolution. But note that Upsample is equivalent to a Deconvolution operator with all weights set to 1.
-
The ROIPooling operator is described in the prototxt as follows:
layer { name: "roi_pool5" type: "ROIPooling" bottom: "conv5_3" bottom: "rois" top: "pool5" roi_pooling_param { pooled_w: 7 pooled_h: 7 spatial_scale: 0.0625 } }
Roi_pooling_param only supports pooled_w, pooled_h, and spatial_scale. The rois input for the Float model is the coordinates outputted from the rpn layer, while the rois input for Fixed and Offline models is the coordinates outputted from the rpn layer multiplied by the spatial_scale value, and then quantized to int16 before being sent to the model.
2. TensorFlow Supported Operators¶
| Operator | Remarks |
|---|---|
| Convolution | Constraints: Kernel_size: H * W < 64 |
| DepthwiseConv2dNative | natively supports Kernel_size of 3*3, 6*6, 9*9, other cases convert to Convolution |
| FullyConnected | |
| Max pooling | |
| Average Pooling | |
| ReLU | |
| PReLU | |
| ReLU6 | |
| LeakyReLU | |
| Sigmoid | |
| Less | |
| Log | |
| Greater | |
| GreaterEqual | |
| Equal | |
| Add | |
| Sub | |
| Mul | |
| RealDiv | only supports the second operand as a constant Tensor |
| FloorDiv | only supports the second operand as a constant Tensor |
| Maximum | |
| Minimum | |
| Mean | |
| Max | |
| Sqrt | |
| Sin | |
| Cos | |
| Rsqrt | |
| Round | |
| Softmax | If you need to compute on a specific dimension, the dimension to be calculated should be transposed to the last dimension (the innermost dimension) |
| FusedBatchNorm | |
| Exp | |
| Align | |
| ConcatV2 | |
| Fill | |
| Gather | only supports the second operand indices as a constant Tensor |
| GatherV2 | |
| Pack | |
| Pad | |
| SpaceToBatchND | |
| BatchToSpaceND | |
| Zeroslike | |
| Split | |
| Slice | |
| Unpack | |
| Tile | |
| Reshape | |
| Transpose | |
| Resize_bilinear | |
| Resize_NearestNeighbor | |
| Batch_matmul | |
| TopKV2 | |
| Tanh | |
| Concatenation | |
| Argmax | |
| Logistic | |
| TransposeConv | |
| Square | |
| StrideSlice | |
| Abs | |
| Sum | |
| Cast |
3. ONNX Supported Operators¶
| 算子 | 备注 |
|---|---|
| Abs | Unlimited |
| Add | Unlimited |
| And | Unlimited |
| ArgMax | axis: Unlimited keepdims: Unlimited select_last_index: Can only be set to 0 |
| ArgMin | axis: Unlimited keepdims: Unlimited select_last_index: Can only be set to 0 |
| Atan | Unlimited |
| AveragePool | auto_pad: Supported, SAME_UPPER, SAME_LOWER or VALID ceil_mode: Supported kernel_shape: If kernel_shape is h*w, it must meet FilterW <= 255, FilterH <= 255 pads: Supports two dimensions, both [0,255] strides: Supports two dimensions, both [0,255] count_include_pad: Unlimited dilation: Only supports 1 If KernelW == InputW and pad_W is 0, then there are no [0, 255] restrictions on kernelW and strideW; Based on this, if KernelH == InputH and pad_H is 0, then kernelH and strideH also have no [0, 255] restrictions |
| BatchNormalization | epsilon: Unlimited momentum: Not supported training_mode: Does not support non-0 is_test: Does not support non-0 spatial: Does not support non-1 |
| Cast | to: Supports float32/float64/int64/int32/bool saturate: Not supported |
| Ceil | Unlimited |
| Clip | Unlimited |
| Concat | 最大支持10000个tensor concat |
| Constant | Unlimited |
| ConstantOfShape | Unlimited |
| Conv | conv1d: All tensor size < 2^31 auto_pad: Supported, SAME_UPPER, SAME_LOWER or VALID dilations: Supported, two dimensions, both [0, 31], exceeding will be optimized internally group: Less than or equal to C kernel_shape: Supported, h * w < 100 pads: Supported, four dimensions, all [0,15], exceeding will generate a separate pad operator strides: Supported, two dimensions, both [0, 31] conv2d: All tensor size < 2^31 auto_pad: Supported, SAME_UPPER, SAME_LOWER or VALID dilations: Supported, two dimensions, both [0, 31], exceeding will be optimized internally group: Less than or equal to C kernel_shape: Supported, h * w < 100 pads: Supported, four dimensions, all [0,15], exceeding will generate a separate pad operator strides: Supported, two dimensions, both [0, 31] conv3d: All tensor size < 2^31 auto_pad: Supported, SAME_UPPER, SAME_LOWER or VALID dilations: Supported, two dimensions, both [0, 31], exceeding will be optimized internally group: Not supported kernel_shape: Supported, h * w < 100, d dimension Unlimited pads: Supported h, w, d three dimensions six directions, all [0, 15], exceeding will generate a separate pad operator strides: Supported h, w two dimensions, both [0, 31], d dimension Unlimited |
| ConvTranspose | All tensor size < 2^31 auto_pad: Supported, SAME_UPPER, SAME_LOWER or VALID dilations: Supported, two dimensions, both [0, 31] group: Less than or equal to C kernel_shape: Supported, h * w < 100 output_padding: Supported output_shape: Not supported pads: Supported strides: Supported, two dimensions |
| Cos | Unlimited |
| CumSum | exclusive: Only supports setting to 0 reverse: Only supports setting to 0 |
| DepthToSpace | blocksize: Supported, the input c dimension must be divisible by blocksize^2 mode: DCR or CRD |
| Div | Unlimited |
| Dropout | is_test: Not supported ratio: Not supported seed: Not supported |
| Einsum | equation: Unlimited Supports both single and double operands, does not support expressions in omitted dimension format |
| Elu | Unlimited |
| Equal | Unlimited |
| Erf | Unlimited |
| Exp | Unlimited |
| Expand | Unlimited |
| Flatten | Unlimited |
| Floor | Unlimited |
| GRU | activation_alpha: Not supported activation_beta: Not supported activations: Only supports sigmoid/tanh clip: Not supported direction: Supports forward and bidirectional layout: Only supports 0 linear_before_offset: Supports 0 and 1 sequence_lens in the input does not support variable |
| Gather | axis: Unlimited indices input supports const and variable |
| GatherElements | axis: Unlimited indices input supports const and variable |
| GatherND | axis: Unlimited indices input supports const and variable |
| Gelu | approximate: Supports None and tanh |
| Gemm | alpha:Unlimited beta:Unlimited transA:Unlimited transB:Unlimited |
| GlobalAveragePool | Unlimited |
| GlobalMaxPool | Unlimited |
| Greater | Unlimited |
| GreaterOrEqual | Unlimited |
| HardSigmoid | alpha:Unlimited beta:Unlimited |
| HardSwish | Unlimited |
| Identity | This operator will be removed during the conversion process |
| InstanceNormalization | epsilon:Unlimited |
| LSTM | activation_alpha: Not supported activation_beta: Not supported activations: Only supports sigmoid/tanh clip: Not supported direction: Only supports forward and bidirectional input_forget: Only supports 0 layout: Only supports 0 sequence_lens in the input does not support variable |
| LayerNormal | axis: Does not support 0 epsilon: Unlimited stash_type: Not supported |
| LayerNormalization | axis: Does not support 0 epsilon: Unlimited stash_type: Not supported |
| LeakyRelu | alpha:Unlimited |
| Less | Unlimited |
| LessOrEqual | Unlimited |
| Log | Unlimited |
| LogSoftmax | Unlimited |
| Logcompress | Unlimited |
| MatMul | Unlimited |
| Max | Unlimited |
| MaxPool | auto_pad: Supported, SAME_UPPER, SAME_LOWER or VALID ceil_mode: Supported kernel_shape: Supported pads: Supported strides: Supported storage_order: Not supported 1, calculated according to 0 If the kernel size is h*w, it must meet FilterW <= 255, FilterH <= 255 |
| MeanVarianceNormalization | Input only supports four dimensions axes: Unlimited |
| Min | Unlimited |
| Mod | Unlimited fmod can only be 0 |
| Mul | Unlimited |
| Neg | Unlimited |
| Not | Unlimited |
| Or | Unlimited |
| PRelu | Unlimited |
| Pad | mode: Supports constant/reflect value: Unlimited Does not support axes as input |
| Pow | Unlimited |
| RNN | activation_alpha: Not supported activation_beta: Not supported activations: Only supports tanh clip: Not supported direction: Only supports forward and bidirectional layout: Only supports 0 sequence_lens in the input only supports empty tensor, does not support variable |
| Range | Unlimited |
| Reciprocal | Unlimited |
| ReduceL2 | axes: Unlimited keepdims: Unlimited noop_with_empty_axes: Only supports 0 |
| ReduceMax | axes: Unlimited keepdims: Unlimited noop_with_empty_axes: Only supports 0 |
| ReduceMean | axes: Unlimited keepdims: Unlimited noop_with_empty_axes: Only supports 0 |
| ReduceMin | axes: Unlimited keepdims: Unlimited noop_with_empty_axes: Only supports 0 |
| ReduceSum | axes: Unlimited keepdims: Unlimited noop_with_empty_axes: Only supports 0 |
| Relu | Unlimited |
| Reshape | allowzero: Only supports 0, does not support 0 values in the output shape |
| Resize | Only supports resizing for hw antialias: Only supports 0 coordinate_transformation_mode: Supports align_corners/asymmetric/half_pixel/pytorch_half_pixel mode: Supports nearest or linear cubic_coeff_a: Not supported exclude_outside: Only supports 0 extrapolation_value: Not supported keep_aspect_ratio_policy: Not supported nearest_mode: Supports, [round_prefer_floor, floor, round_prefer_ceil] |
| Round | Unlimited |
| Scatter | Unlimited |
| ScatterElements | indices support is const tensor and variable tensor axis: Unlimited reduction: Only supports None |
| ScatterND | indices support is const tensor and variable tensor reduction: Only supports None |
| Shape | end:Unlimited start:Unlimited |
| Sigmoid | Unlimited |
| Sign | Unlimited |
| Sin | Unlimited |
| Slice | axes:Unlimited ends:Unlimited starts:Unlimited |
| Softmax | Unlimited |
| Softplus | Unlimited |
| SpaceToDepth | blocksize:Unlimited |
| Split | axis: Unlimited split: Supports up to a maximum of 10000 num_outputs: Supported |
| Sqrt | Unlimited |
| Squeeze | axes:Unlimited |
| Sub | Unlimited |
| Sum | Only supports two inputs |
| Tanh | Unlimited |
| Tile | Unlimited |
| TopK | axis: Unlimited largest: Only supports 1 sorted: Only supports 1 k: Unlimited |
| Transpose | perm:Unlimited |
| Unsqueeze | Unlimited |
| Upsample | Only supports Upsample in the HW dimension, and the scale must be the same mode: Supports nearest and linear height_scale: Unlimited width_scale: Unlimited scales: Unlimited |
| Where | Unlimited |
4. SGS_CHALK支持算子¶
SGS_CHALK各算子具体使用方法请参考: sgs_chalk模块API
| 算子 | 备注 |
|---|---|
| Abs | |
| Add | |
| Alpha_Blending | |
| ArgMin | |
| Argmax | |
| Atan | |
| Atan2 | |
| AveragePool2d | |
| AveragePool3d | |
| BatchMatMul | |
| BatchToSpaceND | |
| BoxDecoder | |
| BoxDecoder2 | |
| Cast | |
| Ceil | |
| Clip | |
| Concatenation | |
| CondGreat | |
| CondLess | |
| Conv2d | |
| Conv3d | |
| Conv3dImageConcat | |
| Cos | |
| Cumsum | |
| CustomNotEqual | |
| CustomPow | |
| CustomizedMaxpool2d | |
| DepthWiseConv2d | |
| Dilation | |
| Div | |
| Elu | |
| Equal | |
| Erf | |
| Exp | |
| Expand_dims | |
| Fill | |
| Floor | |
| Fullyconnected | |
| GRU | |
| Gather | |
| GatherElements | |
| GatherND | |
| Gelu | |
| Greater | |
| GreaterEqual | |
| GroupConv2d | |
| HardSwish | |
| Input | |
| Instancenorm | |
| L2Norm | |
| LSTM | |
| LSTM_caffe | |
| Layernorm | |
| LeakyRelu | |
| Less | |
| LessEqual | |
| Log | |
| Logcompress | |
| LogicalAnd | |
| LogicalNot | |
| LogicalOr | |
| Logistic | |
| MaxPool2d | |
| MaxPool3d | |
| Maximum | |
| Mean | |
| MeanVarianceNorm | |
| Minimum | |
| MirrorPad | |
| Mod | |
| Mul | |
| MultiplyAdd | |
| Negative | |
| NotEqual | |
| Pack | |
| Pad | |
| PhaseModify | |
| PostProcess_Max | |
| PostProcess_Unpack | |
| Prelu | |
| RNN | |
| RSqrt | |
| Range | |
| Reciprocal | |
| ReduceMax | |
| ReduceMin | |
| Relu | |
| Relu1 | |
| Relu6 | |
| Relu_N1_TO_1 | |
| Reshape | |
| ResizeBilinear | |
| ResizeNearestNeighbor | |
| RoiPooling | |
| RootSumSquares2 | |
| Round | |
| ScatterElements | |
| ScatterND | |
| Score_Filter | |
| Select | |
| Shape | |
| Sign | |
| Silu | |
| Sin | |
| Slice | |
| Softmax | |
| Softplus | |
| SpaceToBatchND | |
| Split | |
| Split_V | |
| Sqrt | |
| Square | |
| Squeeze | |
| StridedSlice | |
| Sub | |
| Sum | |
| TFLite_Detection_NMS | |
| Tanh | |
| Tile | |
| TopK | |
| Transpose | |
| TransposeConv2d | |
| Unpack | |
| WiggleErr |
5. IPU Toolchain Model Constraints¶
For Softmax on specific dimensions, we only support operations on the innermost dimension (for multi-dimensional Tensor, we only support Softmax specified on the innermost dimension).
Except for the first Conv layer, the larger the DI dimension (the C dimension in NHWC) for other Conv layers, the higher its efficiency, up to a maximum of 2048.
Math class operators (including Add, Sub, Mul, Div, and other element operation operators) will be more efficient if the right operand is a scaler (single number) or a 1D vector (with the same HW dimension data, different C dimensions).
Try to minimize the situation where the output of one operator is used as input by multiple operators, such as in ResNet's residual structure, GoogLeNet's Inception module, etc. See Construct BW-Friendly Models
6. Model Performance Optimization Guidelines¶
(1) Performance Optimization for Convolutions
kernel size 3x3 is best, especially for the first layer.
When kernel size is 1x1, it is best to align the innermost dimension shape value of the input tensor to 16.
(2) For DMA Operators
- concatenation operator performs better than pack operator.
- split performs better than slice operator.
- Try to minimize transposition on the innermost dimension.
- For single-port elementwise operators, the const operand is best on the right, i.e., input[1].
(3) General Guidelines
- A tensor dimension of 4 is best.
- Align the innermost dimension shape value of the tensor to 32 is best.
- It is best to perform Softmax only on the innermost dimension.
- For ReduceMax, ReduceMin, ReduceSum, it is best if the collapsed dimension is adjacent.
(4) Building BW-Friendly AI Models
BW-friendly AI models refer to models that do not consume system bus BW resources as much as possible, with the BW calculation formula as follows:
BW = Input BW + Output BW + Const BW + Variable BW
where reducing variable BW can enhance model performance, variable BW is influenced by the following two points:
- (1) tensor data volume is too large
- (2) tensor's lifecycle is too long
Example 1: BW-friendly

Example 2: tensor's lifecycle is too long

Example 3: tensor data volume is too large
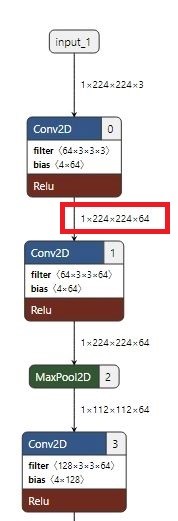
The above pictures show three common model structure diagrams. The structure shown in the first figure complies with the model optimization rules, while the structures shown in the second and third figures will affect model performance. Please minimize the use of structures shown in the second and third figures when building models.