VITS
1 Overview¶
1.1 Background Introduction¶
VITS is an end-to-end speech synthesis algorithm that uses a pre-trained speech encoder to directly convert text into speech without requiring additional intermediate steps or feature extraction. For more details, you can refer to the official VITS link:
https://github.com/jaywalnut310/vits
Since the officially provided VITS model is trained on English, we found another VITS repository trained on Chinese:
https://github.com/ywwwf/vits-mandarin-windows
The model download link is:
https://pan.baidu.com/s/1pN-wL_5wB9gYMAr2Mh7Jvg, password: vits
1.2 Usage Instructions¶
The Linux SDK-alkaid comes with pre-converted offline models and board-side examples by default. The relevant file paths are as follows:
- Board-side example program path Linux_SDK/sdk/verify/opendla/source/tts/vits
- Board-side offline model path Linux_SDK/project/board/${chip}/dla_file/ipu_open_models/tts/vits.img
If the user does not need to convert the model, they can jump directly to section 3.
2 Model Conversion¶
2.1 ONNX Model Conversion¶
-
Setting up the Python environment $conda create -n vits python==3.10 $conda activate vits $git clone https://github.com/ywwwf/vits-mandarin-windows.git $cd vits-mandarin-windows $pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple $cd monotonic_align $python setup.py build_ext --inplace $cd .. Note: The provided Python environment setup is only a reference example; for the specific setup process, please refer to the official source running tutorial:
https://github.com/ywwwf/vits-mandarin-windows/blob/master/README.md -
Model Testing
- Create a models folder and place the downloaded model in this directory, then run the model testing script to ensure the VITS environment is configured correctly $python inference.py
-
Model Modification
-
Modify the original code to change the dynamic length input to fixed length input
-
In the
transforms.pyfile, from line 55 to line 94-
Original code
def unconstrained_rational_quadratic_spline(inputs, unnormalized_widths, unnormalized_heights, unnormalized_derivatives, inverse=False, tails='linear', tail_bound=1., min_bin_width=DEFAULT_MIN_BIN_WIDTH, min_bin_height=DEFAULT_MIN_BIN_HEIGHT, min_derivative=DEFAULT_MIN_DERIVATIVE): inside_interval_mask = (inputs >= -tail_bound) & (inputs <= tail_bound) outside_interval_mask = ~inside_interval_mask outputs = torch.zeros_like(inputs) logabsdet = torch.zeros_like(inputs) if tails == 'linear': unnormalized_derivatives = F.pad(unnormalized_derivatives, pad=(1, 1)) constant = np.log(np.exp(1 - min_derivative) - 1) unnormalized_derivatives[..., 0] = constant unnormalized_derivatives[..., -1] = constant outputs[outside_interval_mask] = inputs[outside_interval_mask] logabsdet[outside_interval_mask] = 0 else: raise RuntimeError('{} tails are not implemented.'.format(tails)) outputs[inside_interval_mask], logabsdet[inside_interval_mask] = rational_quadratic_spline( inputs=inputs[inside_interval_mask], unnormalized_widths=unnormalized_widths[inside_interval_mask, :], unnormalized_heights=unnormalized_heights[inside_interval_mask, :], unnormalized_derivatives=unnormalized_derivatives[inside_interval_mask, :], inverse=inverse, left=-tail_bound, right=tail_bound, bottom=-tail_bound, top=tail_bound, min_bin_width=min_bin_width, min_bin_height=min_bin_height, min_derivative=min_derivative ) return outputs, logabsdet -
Modified code
def unconstrained_rational_quadratic_spline(inputs, unnormalized_widths, unnormalized_heights, unnormalized_derivatives, inverse=False, tails='linear', tail_bound=1., min_bin_width=DEFAULT_MIN_BIN_WIDTH, min_bin_height=DEFAULT_MIN_BIN_HEIGHT, min_derivative=DEFAULT_MIN_DERIVATIVE): inside_interval_mask = (~(inputs < -tail_bound)) & (~(inputs > tail_bound)) outside_interval_mask = ~inside_interval_mask outputs = torch.zeros_like(inputs) logabsdet = torch.zeros_like(inputs) if tails == 'linear': unnormalized_derivatives = F.pad(unnormalized_derivatives, pad=(1, 1)) constant = np.log(np.exp(1 - min_derivative) - 1) unnormalized_derivatives[..., 0] = constant unnormalized_derivatives[..., -1] = constant outputs = inputs * outside_interval_mask else: raise RuntimeError('{} tails are not implemented.'.format(tails)) outputs, logabsdet = rational_quadratic_spline( inputs=inputs, unnormalized_widths=unnormalized_widths, unnormalized_heights=unnormalized_heights, unnormalized_derivatives=unnormalized_derivatives, inverse=inverse, left=-tail_bound, right=tail_bound, bottom=-tail_bound, top=tail_bound, min_bin_width=min_bin_width, min_bin_height=min_bin_height, min_derivative=min_derivative ) outputs = outputs * inside_interval_mask logabsdet = logabsdet * inside_interval_mask return outputs, logabsdet
-
-
models.py- Line 50:
- Original code def forward(self, x, x_mask, w=None, g=None, reverse=False, noise_scale=1.0):
- Modified code def forward(self, x, randn, x_mask, w=None, g=None, reverse=False, noise_scale=1.0):
- Line 90
- Original code z = torch.randn(x.size(0), 2, x.size(2)).to(device=x.device, dtype=x.dtype) * noise_scale
- Modified code z = randn.to(device=x.device, dtype=x.dtype) * noise_scale
-
Lines 167 to 176
-
Original code def forward(self, x, x_lengths): x = self.emb(x) * math.sqrt(self.hidden_channels) # [b, t, h] x = torch.transpose(x, 1, -1) # [b, h, t] x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(x.dtype)
x = self.encoder(x * x_mask, x_mask) stats = self.proj(x) * x_mask m, logs = torch.split(stats, self.out_channels, dim=1) return x, m, logs, x_mask -
Modified code
def forward(self, x, x_mask): x = self.emb(x) * math.sqrt(self.hidden_channels) # [b, t, h] x = torch.transpose(x, 1, -1) # [b, h, t] # x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(x.dtype) x = self.encoder(x * x_mask, x_mask) stats = self.proj(x) * x_mask m, logs = torch.split(stats, self.out_channels, dim=1) return x, m, logs, x_mask
-
-
Line 240
- Original code z = (m + torch.randn_like(m) * torch.exp(logs)) * x_mask
- Modified code z = (m + torch.exp(logs)) * x_mask
-
Lines 499 to 523
-
Original code def infer(self, x, x_lengths, sid=None, noise_scale=1, length_scale=1, noise_scale_w=1., max_len=None): x, m_p, logs_p, x_mask = self.enc_p(x, x_lengths) if self.n_speakers > 0: g = self.emb_g(sid).unsqueeze(-1) # [b, h, 1] else: g = None
if self.use_sdp: logw = self.dp(x, x_mask, g=g, reverse=True, noise_scale=noise_scale_w) else: logw = self.dp(x, x_mask, g=g) w = torch.exp(logw) * x_mask * length_scale w_ceil = torch.ceil(w) y_lengths = torch.clamp_min(torch.sum(w_ceil, [1, 2]), 1).long() y_mask = torch.unsqueeze(commons.sequence_mask(y_lengths, None), 1).to(x_mask.dtype) attn_mask = torch.unsqueeze(x_mask, 2) * torch.unsqueeze(y_mask, -1) attn = commons.generate_path(w_ceil, attn_mask) m_p = torch.matmul(attn.squeeze(1), m_p.transpose(1, 2)).transpose(1, 2) # [b, t', t], [b, t, d] -> [b, d, t'] logs_p = torch.matmul(attn.squeeze(1), logs_p.transpose(1, 2)).transpose(1, 2) # [b, t', t], [b, t, d] -> [b, d, t'] z_p = m_p + torch.randn_like(m_p) * torch.exp(logs_p) * noise_scale z = self.flow(z_p, y_mask, g=g, reverse=True) o = self.dec((z * y_mask)[:,:,:max_len], g=g) return o, attn, y_mask, (z, z_p, m_p, logs_p) -
Modified code
def infer(self, x, x_mask, sid=None, noise_scale=1, z_fixed=None, max_len=None): max_length=1000 x, m_p, logs_p, x_mask = self.enc_p(x, x_mask) if self.n_speakers > 0: g = self.emb_g(sid).unsqueeze(-1) # [b, h, 1] else: g = None randn = z_fixed[:,:2,:500] if self.use_sdp: logw = self.dp(x, randn, x_mask, g=g, reverse=True, noise_scale=self.noise_scale_w) else: logw = self.dp(x, randn, x_mask, g=g) w = torch.exp(logw) * x_mask * self.length_scale # w_ceil = torch.ceil(w) w_ceil = -torch.floor(-w) y_lengths = torch.clamp_min(torch.sum(w_ceil, [1, 2]), 1).long() # y_mask = torch.unsqueeze(commons.sequence_mask(y_lengths, None), 1).to(x_mask.dtype) y_mask = torch.unsqueeze(commons.sequence_mask(y_lengths, max_length), 1).to(x_mask.dtype) attn_mask = torch.unsqueeze(x_mask, 2) * torch.unsqueeze(y_mask, -1) attn = commons.generate_path(w_ceil, attn_mask) m_p = torch.matmul(attn.squeeze(1), m_p.transpose(1, 2)).transpose(1, 2) # [b, t', t], [b, t, d] -> [b, d, t'] logs_p = torch.matmul(attn.squeeze(1), logs_p.transpose(1, 2)).transpose(1, 2) # [b, t', t], [b, t, d] -> [b, d, t'] z_p = m_p + z_fixed * torch.exp(logs_p) * noise_scale[0] z = self.flow(z_p, y_mask, g=g, reverse=True) o = self.dec((z * y_mask)[:,:,:max_len], g=g) # return o, attn, y_mask, (z, z_p, m_p, logs_p) return o, y_lengths
-
- Line 50:
-
attention.pyLines 165 to 170-
Original code
if mask is not None: scores = scores.masked_fill(mask == 0, -1e4) if self.block_length is not None: assert t_s == t_t, "Local attention is only available for self-attention." block_mask = torch.ones_like(scores).triu(-self.block_length).tril(self.block_length) scores = scores.masked_fill(block_mask == 0, -1e4) -
Modified code
if mask is not None: scores = scores.masked_fill(mask == 0, -1e4) scores = scores - (1-mask) * 104 if self.block_length is not None: assert t_s == t_t, "Local attention is only available for self-attention." block_mask = torch.ones_like(scores).triu(-self.block_length).tril(self.block_length) # scores = scores.masked_fill(block_mask == 0, -103) scores = scores - (1-block_mask) * 104
-
-
-
-
Model Export
- Write the model conversion script
export_onnx.py:import os import time import random import numpy as np import torch from scipy.io.wavfile import write import soundfile as sf import commons import utils from models import SynthesizerTrn from text import create_symbols_manager, text_to_sequence, cleaned_text_to_sequence, _clean_text import argparse import onnx from onnxsim import simplify import onnxruntime from thop import profile from torchsummary import summary class AudioGenerator(): def __init__(self, hparams, device): self.hparams = hparams self._device = device if 'language' in hparams.data: symbols_manager = create_symbols_manager(hparams.data.language) else: symbols_manager = create_symbols_manager('default') self.symbol_to_id = symbols_manager._symbol_to_id self.net_g = create_network(hparams, symbols_manager.symbols, device) def load(self, path): load_checkpoint(self.net_g, path) def inference(self, text, phoneme_mode=False): return do_inference(self.net_g, self.hparams, self.symbol_to_id, text, phoneme_mode, self._device) def get_text(text, hparams, symbol_to_id, phoneme_mode=False): if not phoneme_mode: print("1: ", _clean_text(text, hparams.data.text_cleaners)) text_norm = text_to_sequence(text, hparams.data.text_cleaners, symbol_to_id) else: print("2: ", text) text_norm = cleaned_text_to_sequence(text, symbol_to_id) if hparams.data.add_blank: text_norm = commons.intersperse(text_norm, 0) text_norm = torch.LongTensor(text_norm) return text_norm def create_network(hparams, symbols, device): net_g = SynthesizerTrn( len(symbols), hparams.data.filter_length // 2 + 1, hparams.train.segment_size // hparams.data.hop_length, **hparams.model).to(device) _ = net_g.eval() return net_g def load_checkpoint(network, path): _ = utils.load_checkpoint(path, network, None) # Assume the network has loaded weights and are ready to do inference def do_inference(generator, hparams, symbol_to_id, text, phoneme_mode=False, device=torch.device('cpu')): stn_tst = get_text(text, hparams, symbol_to_id, phoneme_mode) with torch.no_grad(): x_tst = stn_tst.to(device).unsqueeze(0).int() x_tst = torch.cat([x_tst, torch.zeros(1, 500 - x_tst.size(1))],dim=1).int() x_tst_lengths = torch.tensor([stn_tst.size(0)])# 1x500 x_mask = torch.unsqueeze(commons.sequence_mask(x_tst_lengths, x_tst.size(1)), 1).float() # noise_scale = 0.667 # noise_scale_w = 0.8 noise_scale = torch.tensor([random.uniform(0, 1)]) noise_scale_w = torch.tensor([random.uniform(0, 1)]) print(f"The noise ncale is {noise_scale}") print(f"The noise scale_w is {noise_scale_w}") max_length=1000 input_tensor = torch.randn(1, hparams.model.hidden_channels, max_length, device="cuda", dtype=torch.float32) z_fixed = torch.randn_like(input_tensor).to(x_tst.device) #audio_pt = generator.infer(x_tst.int(), x_mask, None, noise_scale_w, z_fixed) dummy_input = (x_tst.int(), x_mask, None, noise_scale_w, z_fixed) generator.forward = generator.infer torch.onnx.export( model=generator, args=dummy_input, f='./models/vits.onnx', input_names=["input", "mask", "noise_scale", "z_fixed"], output_names=["z", "y_lengths"], opset_version=13, export_params=True, verbose=False ) model = onnx.load('./models/vits.onnx') model_simp, check = simplify(model) export_name = './models/vits_sim.onnx' onnx.save(model_simp, export_name) # exit(1) # import pdb # pdb.set_trace() np.save("./npy_data/x_tst_0.npy", x_tst) np.save("./npy_data/x_mask_0.npy", x_mask) np.save("./npy_data/noise_scale_w_0.npy", noise_scale_w) np.save("./npy_data/z_fixed_0.npy", z_fixed) onnx_session_static = onnxruntime.InferenceSession('./models/vits_sim.onnx', providers=['TensorrtExecutionProvider', 'CUDAExecutionProvider', 'CPUExecutionProvider']) input_names_static = [input.name for input in onnx_session_static.get_inputs()] output_names_static = [output.name for output in onnx_session_static.get_outputs()] data_static = {input_names_static[0]: np.array(x_tst, dtype=np.int32), input_names_static[1]: np.array(x_mask, dtype=np.float32), input_names_static[2]: np.array(noise_scale_w, dtype=np.float32), input_names_static[3]: np.array(z_fixed, dtype=np.float32),} data_out_static = onnx_session_static.run(output_names_static, data_static) audio=data_out_static[0][0][0] y_length = data_out_static[1] return audio,y_length def save_to_wav(data, sampling_rate, path): sf.write(path, data, 22050, 'PCM_16') if __name__ == "__main__": config_path = "./config/bb_v100.json" hps = utils.get_hparams_from_file(config_path) audio_generator = AudioGenerator(hps, "cpu") checkpoint_path = "./models/G_bb_v100_820000.pth" audio_generator.load(checkpoint_path) phoneme_mode = False do_noise_reduction = True text = "他的到来是一件好事, 我很欢迎他, 大家好, 我是御坂美琴的儿子。" start = time.perf_counter() audio,y_length = audio_generator.inference(text, phoneme_mode) print(f"The inference takes {time.perf_counter() - start} seconds") print(audio.dtype) if do_noise_reduction: import noisereduce as nr # perform noise reduction audio = nr.reduce_noise(y=audio, sr=hps.data.sampling_rate) output_dir = './output/' # python program to check if a path exists # if it doesn’t exist we create one if not os.path.exists(output_dir): os.makedirs(output_dir) filename = 'output.wav' file_path = os.path.join(output_dir, filename) save_to_wav(audio, hps.data.sampling_rate, file_path)
- Write the model conversion script
2.2 Offline Model Conversion¶
2.2.1 Preprocessing & Postprocessing Instructions¶
- Preprocessing The input information for the VITS model is shown in the figure below, and the model has four inputs. Among them, input is the input token_id, mask is used to record the positions of valid token_ids, and noise_scale and z_fixed are random values used to enrich the model's output diversity. Taking Chinese as an example, converting a segment of input text into the model's input requires the following steps: 1) Use the pypinyin package to convert Chinese to Pinyin. 2) Split the Pinyin, look up the index value corresponding to each phoneme through a dictionary, and convert the phonemes to tokens. 3) Pad each token with 0 before and after to indicate pauses. Finally, convert it to token_id.
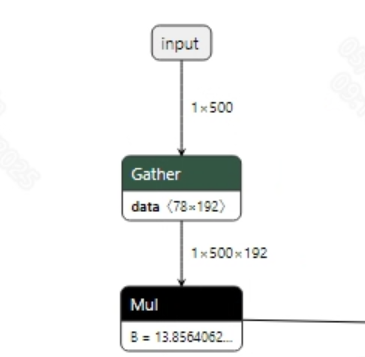
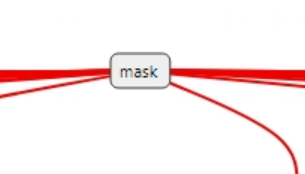
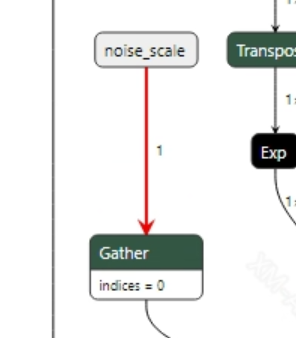

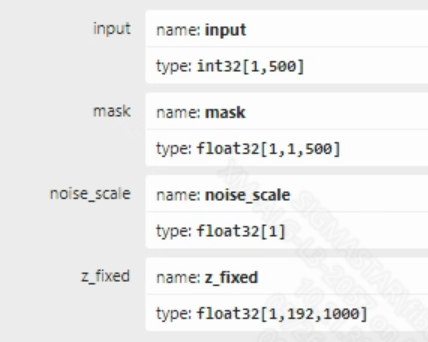
- Postprocessing
VITS does not have postprocessing; the output tensor is directly converted to audio using the wav tool. The model output information is as follows:
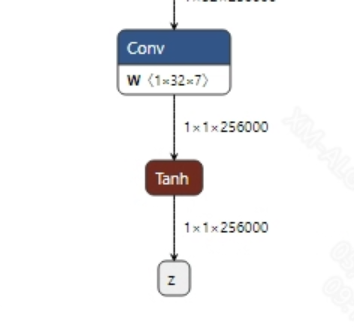
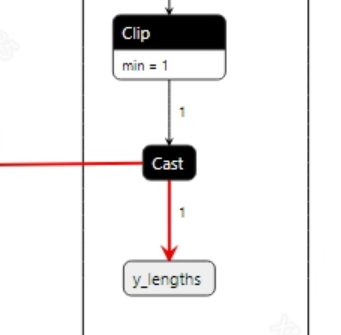
2.2.2 Offline Model Conversion Process¶
Note: 1) OpenDLAModel corresponds to the smodel file extracted from the compressed package image-dev_model_convert.tar. 2) The conversion command needs to be run in a Docker environment; please load the SGS Docker environment according to the Docker development environment tutorial.
- Copy the ONNX model to the conversion code directory $cp models/vits_sim.onnx OpenDLAModel/tts/vits/onnx
- Conversion command $cd IPU_SDK_Release/docker $bash run_docker.sh # Enter the OpenDLAModel directory in the Docker environment $cd /work/SGS_XXX/OpenDLAModel $bash convert.sh -a tts/vits -c config/tts_vits.cfg -p SGS_IPU_Toolchain (absolute path) -s false
- Final generated model locations output/{chip}_/vits.img output/{chip}_/vits_fixed.sim output/{chip}_/vits_float.sim
2.2.3 Key Script Parameter Analysis¶
- input_config.ini
[INPUT_CONFIG]
inputs=speech,mask,noise_scale,z_fixed; # ONNX input node names, separated by commas if there are multiple;
input_formats=RAWDATA_S16_NHWC,RAWDATA_F32_NHWC,RAWDATA_F32_NHWC,RAWDATA_F32_NHWC; # Board-side input formats, can be selected according to ONNX input format, e.g., float: RAWDATA_F32_NHWC, int32: RAWDATA_S16_NHWC;
quantizations=TRUE,TRUE,TRUE,TRUE; # Enable input quantization, do not modify;
[OUTPUT_CONFIG]
outputs=z,y_lengths; # ONNX output node names, separated by commas if there are multiple;
dequantizations=TRUE,TRUE; # Whether to enable dequantization, fill according to actual needs, recommended to be TRUE. If set to False, output will be int16; if set to True, output will be float32.
- tts_vits.cfg
[VITS]
CHIP_LIST=pcupid # Platform name, must match the board platform, otherwise the model cannot run
Model_LIST=vits_sim # Input ONNX model name
INPUT_SIZE_LIST=0 # Model input resolution
INPUT_INI_LIST=input_config.ini # Configuration file
CLASS_NUM_LIST=0 # Just fill in 0
SAVE_NAME_LIST=vits.img # Output model name
QUANT_DATA_PATH=image_lists.txt # Quantization data path
2.3 Model Simulation¶
- Obtain float/fixed/offline model outputs
$bash convert.sh -a tts/vits -c config/tts_vits.cfg -p SGS_IPU_Toolchain (absolute path) -s true
After executing the above command, the
floatmodel's output tensor will be saved by default in a txt file under the pathtts/vits/log/output. In addition, thetts/vits/convert.shscript also provides simulation examples forfixedandoffline; users can obtain outputs for thefixedandofflinemodels by uncommenting code blocks during execution. - Model Accuracy Comparison
With the input being the same as the aforementioned models, enter the environment built in section 2.1, and print the result at line 351 in the
vits-mandarin-windows/export_onnx.pyfile: print(audio) This will obtain the output tensor of the corresponding node in the PyTorch model, allowing for comparison with float, fixed, and offline models. It should also be noted that the original model's output format isNCHW, while the output format of the float/fixed/offline models isNHWC.
3 Board-side Deployment¶
3.1 Program Compilation¶
Before compiling the example program, it is necessary to select the appropriate deconfig based on the board (nand/nor/emmc, ddr model, etc.) for the complete SDK compilation. For details, refer to the alkaid SDK sigdoc document "Development Environment Setup." - Compile the board-side VITS example. $cd sdk/verify/opendla make clean && make source/tts/vits -j8 - Final generated executable file location sdk/verify/opendla/out//app/prog_tts_vits
3.2 Running Files¶
When running the program, you need to copy the following files to the board:
- prog_tts_vits
- vits.img
- zh_tn_tagger.fst
- zh_tn_verbalizer.fst
3.3 Running Instructions¶
-
Usage:
./prog_tts_vits txt model zh_tn_tagger.fst zh_tn_verbalizer.fst(command to run the executable) -
Required Input:
- txt: path to the input text
- model: path to the offline model to be tested
- zh_tn_tagger.fst: third-party resource required for text preprocessing, used for Chinese normalization
- zh_tn_verbalizer.fst: third-party resource required for text preprocessing, used for Chinese normalization
- Example input text: input_word.txt The United States is one of China's trade partners, and the current trade pattern between China and the United States is the result of supply and demand matching and market allocation. Art is the horn of the era's advancement, and artists are the engineers of the soul.
- Typical Output: ./prog_tts_vits resource/input_word.txt models/vits.img resource/wetext/zh_tn_tagger.fst resour ce/wetext/zh_tn_verbalizer.fst input text: The United States is one of China's trade partners, and the current trade pattern between China and the United States is the result of supply and demand matching and market allocation. model invoke time: 2659.814000 ms Generated: 220416 samples of audio 0.000000 -0.000093 0.000521 -0.000707 0.000558 -0.000391 WAV file 'output_0.wav' has been written input text: Art is the horn of the era's advancement, and artists are the engineers of the soul. model invoke time: 2659.969000 ms Generated: 106496 samples of audio 0.000000 -0.000093 0.000521 -0.000707 0.000521 -0.000391 WAV file 'output_1.wav' has been written