PunctuationModel
1 Overview¶
1.1 Background Introduction¶
The punctuation model can accurately predict punctuation marks in the text output of speech recognition models, providing strong support for the speech recognition module and enhancing the readability of the output text.
For more details, please refer to:
https://github.com/yeyupiaoling/PunctuationModel
The model we are using is trained based on the aforementioned GitHub repository, and the training process can be referenced in the training tutorial provided in the official link. The pre-trained model download address is as follows:
https://huggingface.co/nghuyong/ernie-3.0-mini-zh/tree/main
1.2 Usage Instructions¶
The Linux SDK-alkaid comes with pre-converted offline models and board-side examples by default. The relevant file paths are as follows:
- Board-side example program path Linux_SDK/sdk/verify/opendla/source/llm/conformer_punc
- Board-side offline model paths Linux_SDK/project/board/{chip}/dla_file/ipu_open_models/asr/conformer_400x80.img (predecessor model) Linux_SDK/project/board//dla_file/ipu_open_models/llm/punc_sim100.img
- Board-side test audio path Linux_SDK/sdk/verify/opendla/source/resource/BAC009S0764W0121.wav
- Board-side test dictionary path Linux_SDK/sdk/verify/opendla/source/resource/units_asr_punc_lm.txt
If the user does not need to convert the model, they can directly skip to section 3.
2 Model Conversion¶
2.1 onnx Model Conversion¶
-
Setting up the Python environment $conda create -n punc python==3.9 $conda activate punc $conda install paddlepaddle-gpu==2.3.2 cudatoolkit=10.2 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/ $git clone https://github.com/yeyupiaoling/PunctuationModel.git $cd PunctuationModel $python -m pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
Note: The Python environment setup provided here is only for reference; please refer to the official source code running tutorial for specific setup processes:
https://github.com/yeyupiaoling/PunctuationModel?tab=readme-ov-file -
Model testing
Run the inference script; you need to place the trained model
pun_modelsin the models directory $mkdir models $cp -r pun_models ./models $python infer.py -
Model export
-
Install the dependency libraries
$pip install onnx -i https://pypi.tuna.tsinghua.edu.cn/simple $pip install onnx-simplifier -i https://pypi.tuna.tsinghua.edu.cn/simple $pip install onnxruntime -i https://pypi.tuna.tsinghua.edu.cn/simple -
Write the model conversion script
export_onnx_model.pyimport argparse import functools import os import shutil import paddle from paddle.static import InputSpec from utils.logger import setup_logger from utils.model import ErnieLinearExport from utils.utils import add_arguments, print_arguments import numpy as np import onnx import onnxruntime from onnxsim import simplify logger = setup_logger(__name__) parser = argparse.ArgumentParser(description=__doc__) add_arg = functools.partial(add_arguments, argparser=parser) add_arg('punc_path', str, 'dataset/punc_vocab3', 'Path to the punctuation dictionary') add_arg('model_path', str, 'models/iwslt2012_mini_punc3/best_checkpoint', 'Directory to load the checkpoint from') add_arg('infer_model_path', str, 'models/iwslt2012_mini_punc3/pun_models', 'Directory to save the predictions') add_arg('pretrained_token', str, 'pretrained/ernie-3.0-mini-zh', 'Weights of the ERNIE model used') add_arg('input_len', int, 100, 'Input length') args = parser.parse_args() print_arguments(args) def main(): os.makedirs(args.infer_model_path, exist_ok=True) with open(args.punc_path, 'r', encoding='utf-8') as f1, \ open(os.path.join(args.infer_model_path, 'vocab.txt'), 'w', encoding='utf-8') as f2: lines = f1.readlines() lines = [line.replace('\n', '') for line in lines] # num_classes is the size of character classification, number of punctuation plus one for initial space num_classes = len(lines) + 1 f2.write(' \n') for line in lines: f2.write(f'{line}\n') model = ErnieLinearExport(pretrained_token=args.pretrained_token, num_classes=num_classes) model_dict = paddle.load(os.path.join(args.model_path, 'model.pdparams')) model.set_state_dict(model_dict) input_spec = [InputSpec(shape=(-1, -1), dtype=paddle.int64), InputSpec(shape=(-1, -1), dtype=paddle.int64)] paddle.jit.save(layer=model, path=os.path.join(args.infer_model_path, 'model'), input_spec=input_spec) with open(os.path.join(args.infer_model_path, 'info.json'), 'w', encoding='utf-8') as f: f.write(str({'pretrained_token': args.pretrained_token}).replace("'", '"')) logger.info(f'Model exported successfully, saved at: {args.infer_model_path}') # Export ONNX model onnx_save_path = os.path.join(args.infer_model_path, 'model.onnx') input_spec = paddle.static.InputSpec([1, args.input_len], 'int64', 'input') # Specify input shape and data type for the model paddle.onnx.export(model, onnx_save_path, input_spec=[input_spec], opset_version=12) onnx_sim_save_path = os.path.join(args.infer_model_path, f'model_sim{args.input_len}.onnx') onnx_model = onnx.load(f"{onnx_save_path}.onnx") # Load ONNX model model_simp, check = simplify(onnx_model) assert check, "Simplified ONNX model could not be validated" onnx.save(model_simp, onnx_sim_save_path) # Check check_input = np.random.randint(0, 3000, size=(1, args.input_len)).astype('int64') ort_sess = onnxruntime.InferenceSession(onnx_sim_save_path) ort_inputs = {ort_sess.get_inputs()[0].name: check_input} ort_outs = ort_sess.run(None, ort_inputs) model.eval() paddle_input = paddle.to_tensor(check_input) paddle_outs = model(paddle_input) np.testing.assert_allclose(paddle_outs.numpy(), ort_outs[0], rtol=1e-03, atol=1e-05) logger.info(f'ONNX model check succeeded') logger.info(f'ONNX model exported successfully, saved at: {onnx_sim_save_path}') if __name__ == "__main__": main() - Run the model conversion script. $python export_onnx_model.py $mv models/iwslt2012_mini_punc3/pun_models/model_sim100.onnx models/iwslt2012_mini_punc3/pun_models/punc_sim100.onnx
-
2.2 Offline Model Conversion¶
2.2.1 Pre & Post Processing Instructions¶
- Preprocessing The input to the punctuation model is token_id, and it requires using ErnieTokenizer to map the input text. Input information for the punctuation model is as follows:

-
Postprocessing
The punctuation model has no postprocessing; the model output is the prediction results for the input of 100 tokens, indicating whether punctuation should be added after the tokens. Output information for the model is as follows:
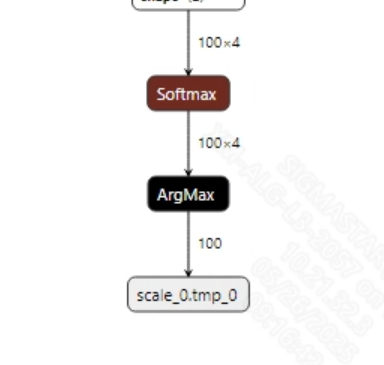
2.2.2 Offline Model Conversion Process¶
Note: 1) OpenDLAModel corresponds to the smodel files extracted from the compressed package image-dev_model_convert.tar. 2) The conversion command needs to be run in the Docker environment; please load the SGS Docker environment according to the Docker development environment tutorial first.
-
Copy the ONNX model to the conversion code directory $cp models/iwslt2012_mini_punc3/pun_models/punc_sim100.onnx OpenDLAModel/llm/punc/onnx
-
Conversion command $cd IPU_SDK_Release/docker $bash run_docker.sh # Enter the OpenDLAModel directory in the docker environment $cd /work/SGS_XXX/OpenDLAModel $bash convert.sh -a llm/punc -c config/llm_punc.cfg -p SGS_IPU_Toolchain (absolute path) -s false
-
Final generated model addresses output/{chip}_/punc_sim100.img output/{chip}_/punc_sim100_fixed.sim output/{chip}_/punc_sim100_float.sim
2.2.3 Key Script Parameter Analysis¶
- input_config.ini
[INPUT_CONFIG]
inputs=inputs; # ONNX input node name, separate with commas if there are multiple;
input_formats=RAWDATA_S16_NHWC; # Board input format, can choose based on the ONNX input format, e.g., float: RAWDATA_F32_NHWC, int32: RAWDATA_S16_NHWC;
quantizations=TRUE; # Enable input quantization, no need to change;
[OUTPUT_CONFIG]
outputs=scale_0.tmp_0; # ONNX output node name, separate with commas if there are multiple;
dequantizations=TRUE; # Whether to enable dequantization, fill according to actual needs, recommended to be TRUE. Set to False, output will be int16; set to True, output will be float32;
- llm_punc.cfg
[COMFORMER]
CHIP_LIST=pcupid # Platform name, must match board platform, otherwise the model will not run
Model_LIST=punc_sim100 # Input ONNX model name
INPUT_SIZE_LIST=0 # Model input resolution
INPUT_INI_LIST=input_config.ini # Configuration file
CLASS_NUM_LIST=0 # Just fill in 0
SAVE_NAME_LIST=punc_sim100.img # Output model name, can be modified
QUANT_DATA_PATH=image_list.txt # Quantization data path
2.3 Model Simulation¶
-
Get float/fixed/offline model output
$bash convert.sh -a llm/punc -c config/llm_punc.cfg -p SGS_IPU_Toolchain (absolute path) -s trueAfter executing the above command, the tensor output of the
floatmodel will be saved by default to a txt file in thellm/punc/log/outputpath. Additionally, thellm/punc/convert.shscript also provides simulation examples forfixedandoffline; users can uncomment the code blocks to obtainfixedandofflinemodel outputs during runtime. -
Model Accuracy Comparison
Under the condition that the input is the same as the above model, enter the environment built in section 2.1. In the
PunctuationModel/utils/model.pyscript, add a print statement after line 91: print(output_data) This will allow you to obtain the output tensor corresponding to the Pytorch model node, and compare it with the float, fixed, and offline models.Additionally, it is important to note that the output format of the original model is
NCHW, while the output formats of the float/fixed/offline models areNHWC.
3 Board-Side Deployment¶
3.1 Program Compilation¶
Before compiling the example program, you need to first select the deconfig for SDK full-package compilation based on the board (nand/nor/emmc, DDR model, etc.), which can be referenced in the alkaid SDK sigdoc document titled "Development Environment Setup."
- Compile the board-side punc example. $cd sdk/verify/opendla $make clean && make source/llm/conformer_punc -j8
- Final generated executable file address sdk/verify/opendla/out/${AARCH}/app/prog_llm_conformer_punc
3.2 Running Files¶
When running the program, the following files need to be copied to the board: - prog_llm_conformer_punc - BAC009S0764W0121.wav - units_asr_punc_lm.txt - conformer_400x80.img - punc_sim100.img
3.3 Running Instructions¶
This example program uses the speech recognition model as a predecessor module for inference.
-
Usage:
./prog_llm_conformer_punc wav asr_model punc_model dict(execution file usage command) -
Required Input:
- wav: input audio
- asr_model: speech recognition model
- punc_model: punctuation recognition model
- dict: dictionary
-
Typical Output: ./prog_llm_conformer_punc resource/BAC009S0764W0121.wav models/conformer_400x80.img models/punc_sim100.img resource/units_asr_punc_lm.txt client [809] connected, module:ipu num_frames: 418, sizeof(inputBuf): 8 am model preprocess time: 236.852000 ms am model invoke time: 96.343000 ms load dict... decode result... punc model invoke time: 10.579000 ms result: 甚至出现交易几乎停滞的情况。 ------shutdown IPU0------ client [809] disconnected, module:ipu