MobileSAM
1 Overview¶
1.1 Background Introduction¶
MobileSAM is a lightweight image segmentation model optimized for mobile devices, capable of recognizing and segmenting any object. It is optimized based on SAM (Segment Anything Model), aiming to maintain high-quality segmentation results while reducing computational complexity and memory usage, enabling efficient operation on resource-constrained mobile devices.
The overall performance of the model is shown below:
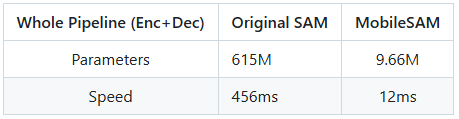
For more details, please refer to the official MobileSAM documentation:
https://github.com/ChaoningZhang/MobileSAM
The download address for the open-source MobileSAM model is as follows:
https://github.com/ChaoningZhang/MobileSAM/blob/master/weights/mobile_sam.pt
1.2 Usage Instructions¶
The Linux SDK-alkaid comes with pre-converted offline models and board-side examples by default. The relevant file paths are as follows:
-
Board-side example program path
Linux_SDK/sdk/verify/opendla/source/vlm/mobilesam -
Board-side offline model path
Linux_SDK/project/board/${chip}/dla_file/ipu_open_models/vlm/mobilesam_sim.img -
Board-side test image path
Linux_SDK/sdk/verify/opendla/source/resource/bus.jpg
If the user does not need to convert the model, they can directly skip to section 3.
2 Model Conversion¶
2.1 onnx Model Conversion¶
-
Setting up the Python environment
$conda create -n mobilesam python==3.10 $conda activate mobilesam $git clone git@github.com:ChaoningZhang/MobileSAM.git $cd MobileSAM $pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simpleNote: The Python environment setup provided here is only for reference; please refer to the official source code running tutorial for specific setup processes: https://github.com/ChaoningZhang/MobileSAM/blob/master/README.md
-
Model testing
-
Write the model testing script
scripts/predict.pyfrom mobile_sam import sam_model_registry, SamAutomaticMaskGenerator, SamPredictor model_type = "vit_t" sam_checkpoint = "./weights/mobile_sam.pt" device = "cuda" if torch.cuda.is_available() else "cpu" mobile_sam = sam_model_registry[model_type](checkpoint=sam_checkpoint) mobile_sam.to(device=device) mobile_sam.eval() predictor = SamPredictor(mobile_sam) predictor.set_image(<your_image>) masks, _, _ = predictor.predict(<input_prompts>) -
Run the model testing script to ensure the mobilesam environment is configured correctly.
$python ./scripts/predict.py
-
-
Model export
-
Modify the model script
- Change the ONNX model input at line 108 in mobile_sam/utils/onnx.py
@torch.no_grad() def forward( self, images: torch.Tensor, point_coords: torch.Tensor): point_labels = torch.tensor([1]).unsqueeze(0) embed_dim = self.model.prompt_encoder.embed_dim embed_size = self.model.prompt_encoder.image_embedding_size mask_input_size = [4 * x for x in embed_size] mask_input = torch.zeros(1, 1, *mask_input_size) has_mask_input = torch.tensor([1]) # get img embedding features = self.model.image_encoder(images) sparse_embedding = self._embed_points(point_coords, point_labels) dense_embedding = self._embed_masks(mask_input, has_mask_input) masks, scores = self.model.mask_decoder.predict_masks( image_embeddings=features, image_pe=self.model.prompt_encoder.get_dense_pe(), sparse_prompt_embeddings=sparse_embedding, dense_prompt_embeddings=dense_embedding, ) if self.use_stability_score: scores = calculate_stability_score( masks, self.model.mask_threshold, self.stability_score_offset ) if self.return_single_mask: masks, scores = self.select_masks(masks, scores, point_coords.shape[1]) return masks, scores
- Change the ONNX model input at line 108 in mobile_sam/utils/onnx.py
-
Write the model conversion script
scripts/export.py:import os,sys sys.path.append(os.getcwd()) import torch from torch.nn import functional as F from torchvision.transforms.functional import resize, to_pil_image from mobile_sam import sam_model_registry from mobile_sam.utils.onnx import SamOnnxModel from mobile_sam import sam_model_registry, SamPredictor import argparse import warnings import cv2 import numpy as np import matplotlib.pyplot as plt from typing import Tuple,Optional import onnx import onnxsim try: import onnxruntime # type: ignore onnxruntime_exists = True except ImportError: onnxruntime_exists = False parser = argparse.ArgumentParser( description="Export the SAM prompt encoder and mask decoder to an ONNX model." ) parser.add_argument( "--checkpoint", type=str, required=True, help="The path to the SAM model checkpoint." ) parser.add_argument( "--output", type=str, required=True, help="The filename to save the ONNX model to." ) parser.add_argument( "--model-type", type=str, required=True, help="In ['default', 'vit_h', 'vit_l', 'vit_b']. Which type of SAM model to export.", ) parser.add_argument( "--return-single-mask", action="store_true", help=( "If true, the exported ONNX model will only return the best mask, " "instead of returning multiple masks. For high resolution images " "this can improve runtime when upscaling masks is expensive." ), ) parser.add_argument( "--opset", type=int, default=16, help="The ONNX opset version to use. Must be >=11", ) parser.add_argument( "--quantize-out", type=str, default=None, help=( "If set, will quantize the model and save it with this name. " "Quantization is performed with quantize_dynamic from onnxruntime.quantization.quantize." ), ) parser.add_argument( "--gelu-approximate", action="store_true", help=( "Replace GELU operations with approximations using tanh. Useful " "for some runtimes that have slow or unimplemented erf ops, used in GELU." ), ) parser.add_argument( "--use-stability-score", action="store_true", help=( "Replaces the model's predicted mask quality score with the stability " "score calculated on the low resolution masks using an offset of 1.0. " ), ) parser.add_argument( "--return-extra-metrics", action="store_true", help=( "The model will return five results: (masks, scores, stability_scores, " "areas, low_res_logits) instead of the usual three. This can be " "significantly slower for high resolution outputs." ), ) def run_export( model_type: str, checkpoint: str, output: str, opset: int, return_single_mask: bool, gelu_approximate: bool = False, use_stability_score: bool = False, return_extra_metrics=False, ): print("Loading model...") sam = sam_model_registry[model_type](checkpoint=checkpoint) onnx_model = SamOnnxModel( model=sam, return_single_mask=return_single_mask, use_stability_score=use_stability_score, return_extra_metrics=return_extra_metrics, ) if gelu_approximate: for n, m in onnx_model.named_modules(): if isinstance(m, torch.nn.GELU): m.approximate = "tanh" embed_dim = sam.prompt_encoder.embed_dim embed_size = sam.prompt_encoder.image_embedding_size mask_input_size = [4 * x for x in embed_size] dummy_inputs = { "images": torch.randn(1, 3, 1024, 1024, dtype=torch.float), "point_coords": torch.randint(low=0, high=1024, size=(1, 1, 2), dtype=torch.int), } _ = onnx_model(**dummy_inputs) output_names = ["masks", "scores"] with warnings.catch_warnings(): warnings.filterwarnings("ignore", category=torch.jit.TracerWarning) warnings.filterwarnings("ignore", category=UserWarning) with open(output, "wb") as f: print(f"Exporting onnx model to {output}...") torch.onnx.export( onnx_model, tuple(dummy_inputs.values()), f, export_params=True, verbose=False, opset_version=opset, do_constant_folding=True, input_names=list(dummy_inputs.keys()), output_names=output_names, ) new_name = "./weights/mobilesam_sim.onnx" model_onnx = onnx.load(f.name) # load onnx model onnx.checker.check_model(model_onnx) # check onnx model model_onnx, check = onnxsim.simplify(model_onnx) onnx.save(model_onnx, new_name) if onnxruntime_exists: ort_inputs = {k: to_numpy(v) for k, v in dummy_inputs.items()} # set cpu provider default providers = ["CPUExecutionProvider"] ort_session = onnxruntime.InferenceSession(output, providers=providers) _ = ort_session.run(None, ort_inputs) print("Model has successfully been run with ONNXRuntime.") def to_numpy(tensor): return tensor.cpu().numpy() if __name__ == "__main__": args = parser.parse_args() run_export( model_type=args.model_type, checkpoint=args.checkpoint, output=args.output, opset=args.opset, return_single_mask=args.return_single_mask, gelu_approximate=args.gelu_approximate, use_stability_score=args.use_stability_score, return_extra_metrics=args.return_extra_metrics, ) # Using an ONNX model ort_session = onnxruntime.InferenceSession(args.output) checkpoint = "./weights/mobile_sam.pt" model_type = "vit_t" image = cv2.imread('./images/picture1.jpg') image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) target_size = (1024, 1024) input_image = np.array(resize(to_pil_image(image), target_size)) input_image_torch = torch.as_tensor(input_image) input_image_torch = input_image_torch.permute(2, 0, 1).contiguous()[None, :, :, :] input_image_torch = np.array(preprocess(input_image_torch)) sam = sam_model_registry[model_type](checkpoint=checkpoint) sam.to(device='cpu') predictor = SamPredictor(sam) predictor.set_image(image) image_embedding = predictor.get_image_embedding().cpu().numpy() input_point = np.array([[400, 400]]) input_label = np.array([1]) # Add a batch index, concatenate a padding point, and transform. # onnx_coord = np.concatenate([input_point, np.array([[0.0, 0.0]])], axis=0)[None, :, :] # onnx_label = np.concatenate([input_label, np.array([-1])], axis=0)[None, :].astype(np.float32) onnx_coord = input_point[None, :, :] # onnx_label = input_label[None, :].astype(np.float32) onnx_coord = predictor.transform.apply_coords(onnx_coord, image.shape[:2]).astype(np.int32) # Create an empty mask input and an indicator for no mask. # onnx_mask_input = np.zeros((1, 1, 256, 256), dtype=np.float32) # onnx_has_mask_input = np.zeros(1, dtype=np.float32) orig_im_size = np.array(image.shape[:2], dtype=np.float32) # Package the inputs to run in the onnx model ort_inputs = { "images": input_image_torch, "point_coords": onnx_coord, } # Predict a mask and threshold it. masks, scores = ort_session.run(None, ort_inputs) print("masks", mask) print("scores", scores) masks = mask_postprocessing(torch.tensor(masks), torch.tensor(orig_im_size)) masks = masks > predictor.model.mask_threshold index = np.argmax(scores) masks = masks[0][index] cv2.imwrite('./mask.png', (np.array(masks).astype(np.int32)*255).reshape(770,769,-1)*np.random.random(3).reshape(1,1,-1)) -
Run the model conversion script, which will generate the mobilesam_sim model in the
weightsdirectory$python ./scripts/export.py \ --checkpoint ./weights/mobile_sam.pt \ --model-type vit_t \ --output ./weights/mobile_sam.onnx
-
2.2 Offline Model Conversion¶
2.2.1 Pre & Post Processing Instructions¶
-
Preprocessing
The input information for the successfully converted mobile_sam.onnx model is shown in the image below. The required input image size is (1, 3, 1024, 1024). Additionally, the pixel values need to be normalized to the range [0, 1].
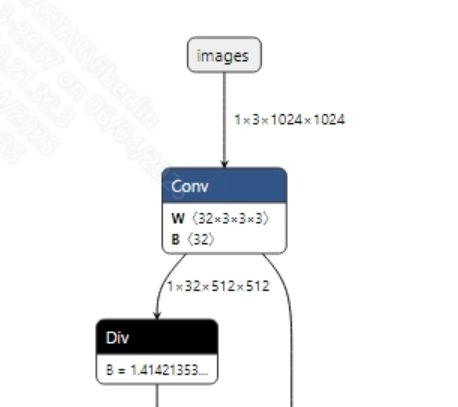
-
Postprocessing
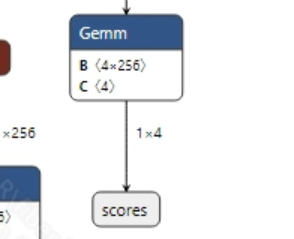
The output information of the mobile_sam.onnx model is shown in the image below. This model has two outputs,
masksandscores, with dimensions of (1, 4, 256, 256) and (1, 4), respectively. After obtaining the model output, it is necessary to process the scores to filter out the index values with the highest probabilities and then pass these to masks for segmentation mask generation.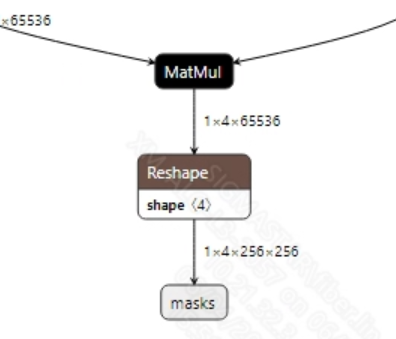
2.2.2 Offline Model Conversion Process¶
Note: 1) OpenDLAModel corresponds to the smodel files extracted from the compressed package image-dev_model_convert.tar. 2) The conversion command needs to be run in the Docker environment; please load the SGS Docker environment according to the Docker development environment tutorial first.
-
Copy the onnx model to the conversion code directory
$cp ./weights/mobile_sam.onnx OpenDLAModel/vlm/mobilesam/onnx -
Conversion command
$cd IPU_SDK_Release/docker $bash run_docker.sh # Enter the OpenDLAModel directory in the docker environment $cd /work/SGS_XXX/OpenDLAModel $bash convert.sh -a vlm/mobilesam -c config/vlm_mobilesam.cfg -p SGS_IPU_Toolchain (absolute path) -s false -
Final generated model address
output/${chip}_${time}/mobilesam_sim.img output/${chip}_${time}/mobilesam_sim_fixed.sim output/${chip}_${time}/mobilesam_sim_float.sim
2.2.3 Key Script Parameter Analysis¶
- input_config.ini
[INPUT_CONFIG]
inputs = images,point_coords; # ONNX input node name, separate with commas if there are multiple;
training_input_formats = RGB,RAWDATA_S16_NHWC; # Input format during model training, usually RGB;
input_formats = BGRA,RAWDATA_S16_NHWC; # Board input format, can choose BGRA or YUV_NV12 as appropriate;
quantizations = TRUE,TRUE; # Enable input quantization, no need to change;
mean_red = 123.675; # Mean value, related to model preprocessing, configure according to actual situation;
mean_green = 116.28; # Mean value, related to model preprocessing, configure according to actual situation;
mean_blue = 103.53; # Mean value, related to model preprocessing, configure according to actual situation;
std_value = 58.395:57.12:57.375; # Standard deviation, related to model preprocessing, configure according to actual situation;
[OUTPUT_CONFIG]
outputs = masks,scores; # ONNX output node name, separate with commas if there are multiple;
dequantizations = TRUE,TRUE; # Whether to enable dequantization, fill in according to actual needs, recommended to be TRUE. Set to False, output will be int16; set to True, output will be float32;
- vlm_mobilesam.cfg
[MOBILESAM]
CHIP_LIST=pcupid # Platform name, must match board platform, otherwise model will not run
Model_LIST=mobilesam_sim # Input ONNX model name
INPUT_SIZE_LIST=0 # Model input resolution
INPUT_INI_LIST=input_config.ini # Configuration file
CLASS_NUM_LIST=0 # Just fill in 0
SAVE_NAME_LIST=mobilesam_sim.img # Output model name
QUANT_DATA_PATH=images_list.txt # Quantization image path
2.3 Model Simulation¶
-
Get float/fixed/offline model output
$bash convert.sh -a vlm/mobilesam -c config/vlm_mobilesam.cfg -p SGS_IPU_Toolchain (absolute path) -s trueAfter executing the above command, the tensor output of the
floatmodel will be saved by default to a txt file in thevlm/mobilesam/log/outputpath. Additionally, thevlm/mobilesam/convert.shscript also provides simulation examples forfixedandoffline; users can uncomment the code blocks to obtainfixedandofflinemodel outputs during runtime. -
Model Accuracy Comparison
Under the condition that the input is the same as the above model, enter the environment built in section 2.1 and run the
MobileSAM/scripts/export.pyscript directly to obtain the output tensor corresponding to the Pytorch model node, and compare it with the float, fixed, and offline models. Additionally, it is important to note that the output format of the original model isNCHW, while the output formats of the float/fixed/offline models areNHWC.
3 Board-Side Deployment¶
3.1 Program Compilation¶
Before compiling the example program, you need to first select the deconfig for SDK full-package compilation based on the board (nand/nor/emmc, DDR model, etc.), which can be referenced in the alkaid SDK sigdoc document titled "Development Environment Setup."
-
Compile the board-side mobilesam example.
$cd sdk/verify/opendla $make clean && make source/vlm/mobilesam -j8 -
Final generated executable file address
sdk/verify/opendla/out/${AARCH}/app/prog_vlm_mobilesam
3.2 Running Files¶
When running the program, the following files need to be copied to the board:
- prog_vlm_mobilesam
- bus.jpg
- mobilesam_sim.img
3.3 Running Instructions¶
-
Usage:
./prog_vlm_mobilesam image model pointW pointH(execution file usage command) -
Required Input:
- image: image folder/path of a single image
- model: path to the offline model to be tested
- pointW: X coordinate of the point on the image
- pointH: Y coordinate of the point on the image
-
Optional Input:
- threshold: detection threshold (0.0~1.0, default is 0.5)
-
Typical output:
./prog_vlm_mobilesam resource/bus.jpg models/mobilesam_sim.img 270 600 client [758] connected, module:ipu found 1 images! [0] processing resource/bus.jpg... fillbuffer processing... net input width: 1024, net input height: 1024 img model invoke time: 635.592000 ms postprocess time: 41.640000 ms out_image_path: ./output/752093/images/bus.png ------shutdown IPU0------ client [758] disconnected, module:ipu
