SCL Debug SOP
REVISION HISTORY¶
| Revision No. | Description |
Date |
|---|---|---|
| 1.0 | 12/07/2023 |
前言¶
本文为FAE及软件开发相关人员而写,旨在介绍开发过程中客户遇到scl相关问题时,如何自行进行初步排查,确定是sgs SDK问题后再提供相关信息给FAE分析。
1. 掉帧,帧率不稳定¶
debug 流程参考图:

TIPS : 首先理清楚是否是本模块的问题。

判断input 帧率 是否足够
如果input fps 满足要求,那就是本模块问题。
如果input fps 不满足要求, 但是rewindcnt > 0,或者dropcnt > 0, 并且在持续增加,那就是SCL模块问题, 否则就要分析前级。
1.1 偶尔掉帧¶
echo 4 > /proc/mi_modules/mi_scl/debug_level; echo fpsth [chnid] [portid] [fpsth] [fpsfloatth] > /proc/mi_modules/mi_scl/mi_scl[x];
fpsth 为fps整数位
fpsfloatth 为fps小数位(乘以1000)
设置帧率阈值,小于阈值会打印在串口,确认在帧率波动过程中没有对模块做任何操作。
在帧率正常情况下抓一次proc, 帧率出现波动之后再抓一次,然后把log提供给FAE分析
1.2 帧率稳定,但是没有达到预期帧率¶
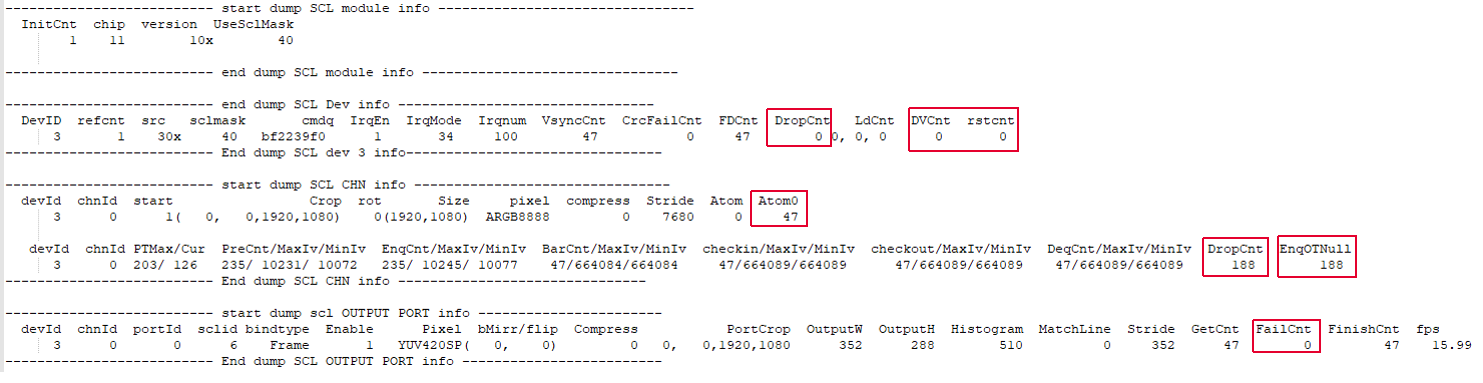
如果是本模块开始的掉帧,观察proc信息的以下几个栏位, 分硬件和软件两种情况:
1.2.1 排查原因¶
在“SCL CHN Info”中dropcnt不为0,并且持续增加。代表软件发生drop。
1.2.1.1 拿不到output buffer 情况
EnqOTNull不为0,所有的output都拿不到output buffer;“scl OUTPUT PORT info”中FailCnt不为0,对应的port拿不到output buffer

拿不到output buffer 分为以下4种情况(如上图红框), 请观察其中哪个持续上涨并在下方找到对应的debug 方式,之后请把实验结论告知FAE。
GetIntoMaxCnt: max enque cnt超过限制
实验case如下,并且将实验结论与log 发给FAE分析:
-
加大Max_EnqTasks Cnt:
echo set_Max_EnqTasks [modid] [devid] [pass] [chn] [cnt] > /proc/mi_modules/mi_sys/mi_sys0; //cnt 默认为2, 可以增加到4左右。
-
清除模块肚子里缓存的buffer:
echo clearbindq [chnid] [bclear] > /proc/mi_modules/mi_scl/mi_scl[x] exp: echo clearbindq [chnid] 1 > /proc/mi_modules/mi_scl/mi_scl[x]

看到atom=0 之后再关闭清除动作
echo clearbindq [chnid] 0 > /proc/mi_modules/mi_scl/mi_scl[x]
如果关闭清除动作之后帧率正常,atom <=2,那是初始化过程中堆积buffer导致。
Modparam.json 设置初始化参数,Chndbglv和ChnMaxEnqTasks, 前面两个参数是DevId/ChnId。
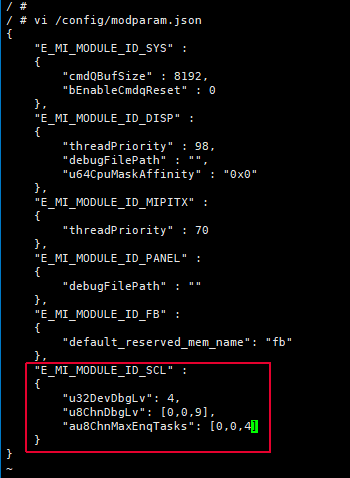
-
如果看到atom 等于设置的max enqTask cnt, 可以抓以下log:
echo 4 > /proc/mi_modules/mi_scl/debug_level; (跑应用之前) echo debuglv [chnid] 9 > /proc/mi_modules/mi_scl/mi_scl[x]; echo debuglv 4 > /proc/mi_modules/mi_scl/mi_scl[x]; echo clearbindq [chnid] 1 > /proc/mi_modules/mi_scl/mi_scl[x]; cat /proc/kmsg; echo clearbindq [chnid] 0 > /proc/mi_modules/mi_scl/mi_scl[x];
提供proc & kmsg 给FAE 观察enque task cnt 涨上来的过程时序是否合理。
-
如果关闭清除动作之后帧率正常,且2 < atom < max enq task cnt, 也按照上一步的命令抓log信息给FAE分析是否处于规格临界情况。
GetIntoMmaLackCnt: mma内存不够
将问题现象告知FAE,请SYS owner 协助调整 MMA内存。
GetIntoTotalCnt: total buffer depth 使用完
echo debug_frc on [Modid] [Devid] [Chnid] [Passid] [Portid] out > /proc/mi_modules/mi_sys/mi_sys0;
会将depth用完时buffer 分布情况打印在串口,如果打印狂刷会有影响,可以
echo 0 > /proc/sys/kernel/printk;
关掉打印, 使用cat /proc/kmsg抓信息。观察哪里占用的buffer比较多。 一般情况下sys 会限制模块拿到手上的buffer 数量2张,所以不会是本模块拿的多,一般是output port depth不够,或者在后级bindQ中没有及时取走。 如果是depth不够可以
echo set_ouputport_depth [Modid] [Devid] [Chnid] [Passid] [Portid] u32UserFrameDepth u32BufQueueDepth > /proc/mi_modules/mi_sys/mi_sys0
增加depth再去观察哪里占用buffer较多。如果增加depth 帧率上去了, 但是应用场景要省内存就要抓前后级模块proc信息和硬件处理的active 时间提供给FAE 分析是否合理。
如果是后级bindQ中占用较多,请后级模块owner分析。
GetIntoFrcCnt:帧率控制情况丢帧
可以观察后级proc是否有设置帧率控制,如果有设置并且设置正确,但是没有达到预期帧率,请FAE联系后级owner帮忙分析。
1.2.1.2 软件塞buffer给硬件速度慢的情况
如果在proc信息中没有看到drop cnt计数, 但是Atom0计数稳定增加,说明硬件性能有空闲,软件塞buffer不够及时。

解决步骤:
-
拉高模块线程优先级
确认目前CPU loading 是否比较高,提高scl 线程优先级,默认为98,如果当前chip支持多核也可以将scl线程设置到其它空闲的核试试;
Modparam.json scl 增加参数 :
u32threadPriorityArray = [99], 下标为Devid,设置线程优先级99。
u16CpuMaskAffInityArray = [6], 下标为Devid, 数值0:default use all cpu, bit0~3 代表cpu0~3, 例如6代表Dev0线程use cpu1 & cpu2。
"E_MI_MODULE_ID_SCL" : { "u32threadPriorityArray": [99], "u16CpuMaskAffInityArray": [6] }, -
抓时序log,理清是哪里耗时久,请FAE 进场分析:
echo 4 > /proc/mi_modules/mi_scl/debug_level; echo debuglv [chnid] 9 > /proc/mi_modules/mi_scl/mi_scl[x]; echo debuglv 4 > /proc/mi_modules/mi_scl/mi_scl[x];
2. 不出图¶
2.1 是否有消费者¶
只有在有消费者的情况下,模块才会工作,消费者只有user 或者bind 后级。
所以要确认 user depth > 0, 或者bind 后级,并且都有enable,scl enable由MI_SCL_StartChannel API决定。

2.2 是否前级有送流¶
判断input 帧率是否大于0
如果input 帧率大于0, 但是rewindcnt > 0,或者dropcnt > 0, 并且在持续增加,需要抓log ,请FAE进场分析。
echo 4 > /proc/mi_modules/mi_scl/debug_level; echo debuglv [chnid] 255 > /proc/mi_modules/mi_scl/mi_scl[x]; echo debuglv 255 > /proc/mi_modules/mi_scl/mi_scl[x]; cat /proc/kmsg
3. 图像花屏¶
3.1 前级图像已花屏¶
使用以下命令做scl pattern实验
echo patengen [chnid] [bEn] 0 > /proc/mi_modules/mi_scl/mi_scl[x];
如果不会发生花屏,那么比较有可能是输入源就已经花屏,如果source是frame mode情况下再使用以下命令dump输入和输出,确定是前级送进来的内容就已经有问题,转前级进场分析,如果source是realtime mode就不需要dump了,直接请前级分析
echo dumptaskfile [chnid] 2 [path] > /proc/mi_modules/mi_scl/mi_scl[x];
3.2 本模块问题¶
如果使用scl pattern仍然花屏,那么可以查看scl proc信里面的'DVCnt'字段有没有持续增加,如果有持续增加,那做以下实验:
- 提高scl clk到最大,加快处理速度。cat /proc/mi_modules/mi_scl/debug_hal/clk, 查看支持的clk, echo [clk] > /proc/mi_modules/mi_scl/debug_hal/clk 设置clk。
- 如果提高scl clk到最大,'DVCnt'字段仍然持续增加,那么需要增大前端sensor的 h blank来测试,具体方法需请FAE提供
如上两个方法,问题仍然未解决,那么请FAE进场分析
4. 踩内存¶
4.1 增大复现几率¶
如果是低概率问题,需要打开debug mmu功能(能增大复现几率),然后再尝试复现 修改modparam.json,在E_MI_MODULE_ID_SYS节点增加 "debugMmu":true
"E_MI_MODULE_ID_SYS" :
{
"debugMmu": true
},
4.2 使用以下命令抓log,请FAE进场分析¶
echo 4 > /proc/mi_modules/mi_scl/debug_level echo debuglv [chnid] 1 > /proc/mi_modules/mi_scl/mi_scl[x]; echo debug_mmu debug_log 1 > /proc/mi_modules/mi_sys/mi_sys0 cat /proc/kmsg
5. cmdq timeout¶
5.1 realtime mode¶
如果scl前面都是realtime绑定的情况下,出现问题先查看vif端是否正常
cat /proc/mi_modules/mi_vif/debug_hal/vif0/vif_ints
查看Interval(帧间隔)时间是否正常,VREF_RISING是否在稳定增加,如果不正常,那么先请FAE进场协助分析VIF模块,否则,使用以下命令抓log,提供给FAE分析SCL模块
echo 4 > /proc/mi_modules/mi_scl/debug_level cat /proc/kmsg
5.2 frame mode¶
使用以下命令抓log,请FAE进场分析
echo 4 > /proc/mi_modules/mi_scl/debug_level cat /proc/kmsg
6. 画面模糊¶
6.1 前级送流画面是否正常¶
使用以下命令dump输入,先排除输入的图像是否正常
echo dumptaskfile [chnid] 2 [path] > /proc/mi_modules/mi_scl/mi_scl[x];