YOLO-World
1 概述¶
1.1 背景介绍¶
YOLO-World是一种创新的实时开放词汇表目标检测方法, 通过引入视觉-语言建模技术, 使得检测器能够理解和识别未在训练数据中出现过的新对象类别。 yolov8-world引进了该实时开放词汇表目标检测方法, 可根据描述性文本检测图像中的任何物体。yolov8-world可大幅降低计算要求, 同时保持极具竞争力的性能。yolov8-world有提供多种不同大小的模型:s、m、l这些开源模型的精度如下:
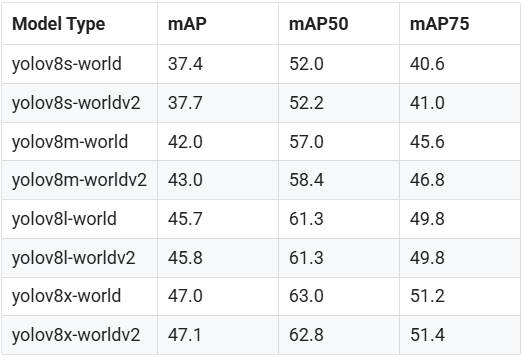
详情可参考yolov8-world官方说明
https://docs.ultralytics.com/models/yolo-world/#available-models-supported-tasks-and-operating-modes
源码如下:
https://github.com/ultralytics/ultralytics/blob/v8.2.32/ultralytics/engine/exporter.py
yolov8开源模型下载地址如下:
1.2 使用说明¶
Linux SDK-alkaid中默认带了已经预先转换好的离线模型及板端示例, 相关文件路径如下:
-
板端示例程序路径
Linux_SDK/sdk/verify/opendla/source/vlm/yolo_world -
板端离线模型路径
Linux_SDK/project/board/${chip}/dla_file/ipu_open_models/vlm/yolov8s_world_image_encode.img Linux_SDK/project/board/${chip}/dla_file/ipu_open_models/vlm/yolov8s_world_text_encode.img -
板端测试图像路径
Linux_SDK/sdk/verify/opendla/source/resource/bus.png
如果用户不需要转换模型可直接跳转至第3章节。
2 模型转换¶
2.1 onnx模型转换¶
-
python环境搭建
$conda create -n yolov8 python==3.10 $conda activate yolov8 $git clone https://github.com/ultralytics/ultralytics $cd ultralytics $pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple注意:这里提供的python环境搭建, 仅作为参考示例, 具体搭建过程请参考官方源码运行教程:
https://docs.ultralytics.com/quickstart/ -
模型测试
-
创建yolov8-world目录并编写模型测试脚本
predict.pyfrom ultralytics import YOLOWorld # Initialize a YOLO-World model model = YOLOWorld("./yolov8-world/yolov8s-world.pt") # or select yolov8m/l-world.pt for different sizes # Execute inference with the YOLOv8s-world model on the specified image results = model.predict("path/to/image.jpg") # Show results results[0].show() -
运行模型测试脚本, 确保yolov8环境配置正确。
$python ./yolov8-world/predict.py
具体可参考yolov8官方测试文档
https://docs.ultralytics.com/zh/models/yolo-world/#predict-usage -
-
模型导出
-
修改模型脚本
-
在exporter.py第233行处插入
text = torch.randn((1,1,512),dtype=float).to(self.device) -
在exporter.py第268行处插入
self.text = text -
在exporter.py第409~419行处修改
-
原始代码
torch.onnx.export( self.model.cpu() if dynamic else self.model, # dynamic=True only compatible with cpu self.im.cpu() if dynamic else self.im, f, verbose=False, opset_version=opset_version, do_constant_folding=True, # WARNING: DNN inference with torch>=1.12 may require do_constant_folding=False input_names=["images"], output_names=output_names, dynamic_axes=dynamic or None, ) -
修改代码
torch.onnx.export( self.model.cpu() if dynamic else self.model, # dynamic=True only compatible with cpu (self.im.cpu(),False,False,self.text) if dynamic else (self.im,False,False,self.text), f, verbose=False, opset_version=opset_version, do_constant_folding=True, input_names=["images", "profile", "visualize", "text_feats"], output_names=output_names, dynamic_axes=dynamic or None, )
-
-
-
编写模型转换脚本
export.py:import os import sys sys.path.append(os.getcwd()) from typing import Union, List, Tuple from ultralytics import YOLOWorld import clip import torch.nn as nn import torch import onnx import onnxruntime import onnxsim device = torch.device("cuda" if torch.cuda.is_available() else "cpu") class TextModelWrapper(nn.Module): def __init__(self, clip_model_name: str, device: torch.device = "cuda" if torch.cuda.is_available() else "cpu", ): super().__init__() # check model info self.clip_model_name = clip_model_name self.device = device # load CLIP self.model = clip.load(clip_model_name)[0] self.model.float() self.model.eval() # load tokenize def forward(self, tokens): tokens = tokens.to(self.device).to(torch.int32) text_features = self.model.encode_text(tokens).float() text_features = text_features.mean(axis=0, keepdim=True) text_features_norm = text_features / text_features.norm(dim=-1, keepdim=True) return text_features_norm clip_text = TextModelWrapper("./yolov8-world/ViT-B-32.pt", device= device) text='person' text_token = clip.tokenize(text).to('cpu') text_token = text_token.split(80)[0].split(80)[0] f='./yolov8-world/clip_text_encode.onnx' with torch.no_grad(): torch.onnx.export( clip_text, text_token, f, opset_version=13, input_names=['text'], output_names=['text_feats'], do_constant_folding=False) model_onnx = onnx.load(f) model_onnx, check = onnxsim.simplify(model_onnx) onnx.save(model_onnx, f) model = YOLOWorld("./yolov8-world/yolov8s-worldv2.pt") # load a pretrained model (recommended for training) model.set_classes(["person"]) path = model.export(format="onnx",imgsz=[640, 640], simplify=True, opset=13) # export the model to ONNX format -
运行模型转换脚本, 会在
yolov8-world目录下生成clip_text_encode.onnx和yolov8s-worldv2.onnx模型$python ./yolov8-world/export.py
-
2.2 离线模型转换¶
2.2.1 预&后处理说明¶
-
预处理
转换成功的yolov8s-worldv2.onnx模型输入信息如下图所示, 该模型存在两个输入:图像输入和文本embedding输入。其中图像输入的维度为 (1, 3, 640, 640), 文本embedding输入的维度为(1, 1, 512), 此外图像输入需要将像素值归一化到 [0, 1] 范围内。
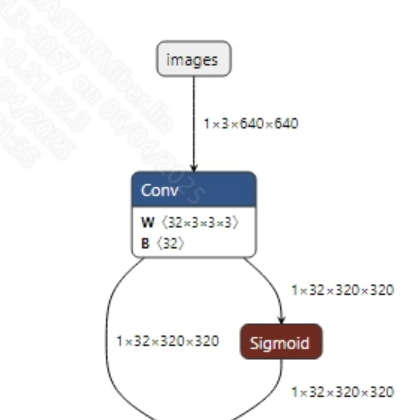
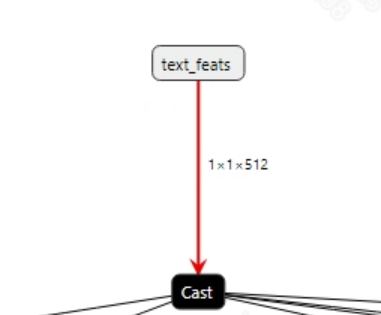
转换成功的clip_text_encode.onnx模型输入信息如下图所示, 要求输入图像的尺寸为 (1, 77), 不需要额外的前处理。
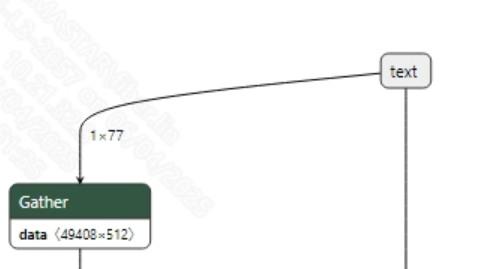
-
后处理
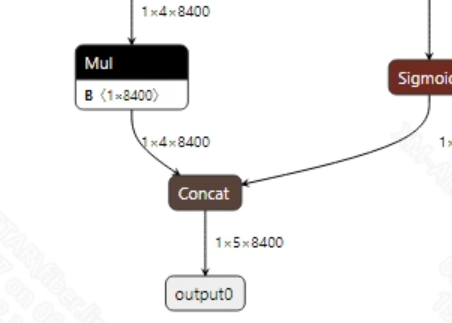
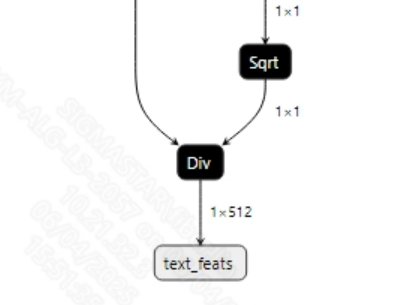
yolov8s-worldv2.onnx和clip_text_encode.onnx模型的输出信息如下图所示, 图像模型的输出维度为(1, 5, 8400)和(1, 1, 512), 文本模型的输出维度为(1, 512)。其中, 文本模型的输出将作为图像模型的输入;图像模型的输出维度中, 8400是候选框的数量, 5表示4个边界框坐标和1个类别概率。获取到模型输出的候选框后, 需要对所有候选框的类别进行判断以及NMS非极大值抑制操作后才能输出正确的坐标框。(如果想要检测到更多的类别, 需要在onnx模型转换时, 增加输入的类别)
2.2.2 offline模型转换流程¶
注意:1)OpenDLAModel对应的是压缩包image-dev_model_convert.tar解压之后的smodel文件。2)转换命令需要在docker环境下运行, 请先根据Docker开发环境教程, 加载SGS Docker环境。
-
拷贝onnx模型到转换代码目录
$cp ./yolov8-world/yolov8s-worldv2.onnx OpenDLAModel/vlm/yolov8-wolrd/onnx $cp ./yolov8-world/clip_text_encode.onnx OpenDLAModel/vlm/yolov8-wolrd/onnx -
转换命令
$cd IPU_SDK_Release/docker $bash run_docker.sh #进入到docker环境下的OpenDLAModel目录 $cd /work/SGS_XXX/OpenDLAModel $bash convert.sh -a vlm/yolov8_world -c config/vlm_yoloworld.cfg -p SGS_IPU_Toolchain(绝对路径) -s false -
最终生成的模型地址
output/${chip}_${时间}/yolov8_world_image_encode.img output/${chip}_${时间}/yolov8_world_image_encode_fixed.sim output/${chip}_${时间}/yolov8_world_image_encode_float.sim output/${chip}_${时间}/yolov8_world_text_encode.img output/${chip}_${时间}/yolov8_world_text_encode_fixed.sim output/${chip}_${时间}/yolov8_world_text_encode_float.sim
2.2.3 关键脚本参数解析¶
- input_config_img.ini
[INPUT_CONFIG]
inputs = images,text_feats; #onnx 输入节点名称, 如果有多个需以“,”隔开;
training_input_formats = RGB,RAWDATA_F32_NHWC; #模型训练时的输入格式, 通常都是RGB;
input_formats = YUV_NV12,RAWDATA_F32_NHWC; #板端输入格式, 可以根据情况选择BGRA或者YUV_NV12;
quantizations = TRUE,TRUE; #打开输入量化, 不需要修改;
mean_red = 0; #均值, 跟模型预处理相关, 根据实际情况配置;
mean_green = 0; #均值, 跟模型预处理相关, 根据实际情况配置;
mean_blue = 0; #均值, 跟模型预处理相关, 根据实际情况配置;
std_value = 255; #方差, 跟模型预处理相关, 根据实际情况配置;
[OUTPUT_CONFIG]
outputs = output0; #onnx 输出节点名称, 如果有多个需以“,”隔开;
dequantizations = TRUE; #是否开启反量化, 根据实际需求填写, 建议为TRUE。设为False, 输出为int16; 设为True, 输出为float32
[OPTIMIZE_CONFIG]
Light_Offline_Model=TRUE;
- input_config_text.ini
[INPUT_CONFIG]
inputs = text; #onnx 输入节点名称, 如果有多个需以“,”隔开;
input_formats = RAWDATA_U16_NHWC; #板端输入格式, 可以根据情况选择BGRA或者YUV_NV12;
quantizations = TRUE; #打开输入量化, 不需要修改;
[OUTPUT_CONFIG]
outputs = test_feats; #onnx 输出节点名称, 如果有多个需以“,”隔开;
dequantizations = TRUE; #是否开启反量化, 根据实际需求填写, 建议为TRUE。设为False, 输出为int16; 设为True, 输出为float32
[OPTIMIZE_CONFIG]
optimize_layernorm_precision=TRUE; #算子优化
optimize_Instancenorm_precision=TRUE; #算子优化
- vlm_yolov8_world.cfg
[YOLOWORLD]
CHIP_LIST=pcupid #平台名称, 必须和板端平台一致, 否则模型无法运行
Model_LIST=yolov8s-worldv2.onnx,clip_text_encode #输入onnx模型名称
INPUT_SIZE_LIST=0,0 #模型输入分辨率
INPUT_INI_LIST=input_config_img.ini,input_config_text.ini #配置文件
CLASS_NUM_LIST=0,0 #填0即可
SAVE_NAME_LIST=yolov8_world_image_encode.img,yolov8_world_text_encode.img #输出模型名称
QUANT_DATA_PATH=images_list.txt,quant_data_txt #量化图片路径
2.3 模型仿真¶
-
获取float/fixed/offline模型输出
$bash convert.sh -a vlm/yolov8_wolrd -c config/vlm_yoloworld.cfg -p SGS_IPU_Toolchain(绝对路径) -s true执行上述命令后, 会默认将
float模型的输出tensor保存到vlm/yolov8_world/log/output路径下的txt文件中。此外, 在vlm/yolov8_world/convert.sh脚本中也提供了fixed和offline的仿真示例, 用户在运行时可以通过打开注释代码块, 分别获取fixed和offline模型输出。 -
模型精度对比
在保证输入和上述模型相同的情况下, 进入2.1章节搭建好的环境, 在
ultralytics/nn/modules/head.py文件的第249行处添加打印:print(y)文本模型的精度验证可参考
CLIP算法。即可获取pytorch模型对应节点的输出tensor, 进而和float、fixed、offline模型进行对比。此外需要特别注意的是, 原始模型的输出格式是NCHW, 而float/fixed/offline模型输出的格式是NHWC。
3 板端部署¶
3.1 程序编译¶
示例程序编译之前需要先根据板子(nand/nor/emmc, ddr型号等)选择deconfig进行sdk整包编译, 具体可以参考alkaid sdk sigdoc《开发环境搭建》文档。
-
编译板端yolov8_world示例。
$cd sdk/verify/opendla $make clean && make source/vlm/yolov8_world -j8 -
最终生成的可执行文件地址
sdk/verify/opendla/out/${AARCH}/app/prog_vlm_yolov8_world
3.2 运行文件¶
运行程序时, 需要先将以下几个文件拷贝到板端
- prog_vlm_yolov8_world
- bus.png
- yolov8_world_image_encode.img
- yolov8_world_text_encode.img
3.3 运行说明¶
-
Usage:
./prog_vlm_yolov8_world image text imgModel textModel dict(执行文件使用命令) -
Required Input:
- image: 图像文件夹/单张图像路径
- text: 文本描述如“person”, "cars"。由于该模型转换时只设置单类, 因此不能输入“person, cars”这样的多类别描述。
- imgModel: 需要测试的offline模型路径
- textModel: 需要测试的offline模型路径
- dict: 字典
-
Typical output:
./prog_vlm_yolo_world resource/bus.jpg "person" models/yolov8_world_image_encode.img models/yolov8_world_text_encode.img resource/en_vocab.txt client [745] connected, module:ipu text/img model input nums: 1, 2 found 1 images! text model invoke time: 25.727000 ms [0] processing resource/bus.jpg... fillbuffer processing... net input width: 640, net input height: 640 img model invoke time: 101.744000 ms postprocess time: 0.878000 ms outImagePath: ./output/705695/bus.png ------shutdown IPU0------ client [745] disconnected, module:ipu
