Conformer
1 概述¶
1.1 背景介绍¶
Conformer模型是一种结合了Transformer的自注意力机制和CNN卷积模块的混合模型, 主要用于语音识别领域, 能够将输入的音频转换为对应的文本序列, 具体精度情况如下:
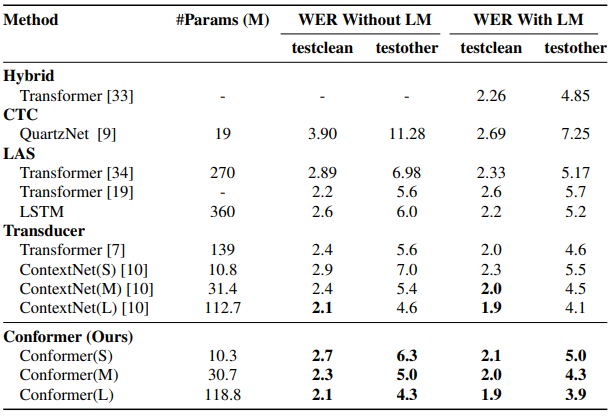
由于Conformer官方未提供模型权重, 本项目的模型来源于Wenet框架。Wenet所开源的Conformer模型列表如下:
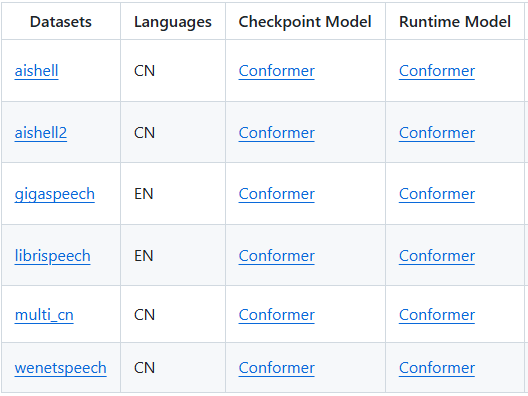
详情可参考wenet官方文档:
https://github.com/wenet-e2e/wenet/blob/v3.0.1/docs/pretrained_models.md
我们所采用是基于wenetspeech训练的Checkpoint Model, 下载地址为:
https://wenet.org.cn/downloads?models=wenet&version=wenetspeech_u2pp_conformer_exp.tar.gz
1.2 使用说明¶
Linux SDK-alkaid中默认带了已经预先转换好的离线模型及板端示例, 相关文件路径如下:
-
板端示例程序路径
Linux_SDK/sdk/verify/opendla/source/asr/conformer -
板端离线模型路径
Linux_SDK/project/board/${chip}/dla_file/ipu_open_models/asr/conformer_400x80.img -
板端测试音频路径
Linux_SDK/sdk/verify/opendla/source/resource/BAC009S0764W0121.wav -
板端测试字典路径
Linux_SDK/sdk/verify/opendla/source/resource/units_asr_punc_lm.txt
如果用户不需要转换模型可直接跳转至第3章节。
2 模型转换¶
2.1 onnx模型转换¶
-
python环境搭建
$conda create -n wenet python==3.9 $conda activate wenet $git clone https://github.com/wenet-e2e/wenet.git $cd wenet $pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple注意:我们是基于wenet-v3.0.1版本上进行开发的, 这里提供的python环境搭建, 仅作为参考示例, 具体搭建过程请参考官方源码运行教程:
https://github.com/wenet-e2e/wenet/tree/v3.0.1 -
模型测试
-
编写模型测试脚本
predict.pyimport wenet model = wenet.load_model('chinese') # or model = wenet.load_model(model_dir='xxx') result = model.transcribe('audio.wav') print(result['text']) -
运行模型测试脚本, 确保wenet环境配置正确。
$python predict.py
注意:这里的测试demo示例来源于官方源码运行教程,
audio.wav需要用户自己准备, 可以参考test/resources下的音频, 并且放到predict.py同级目录下。 -
-
模型导出
-
安装依赖库
$pip install onnx -i https://pypi.tuna.tsinghua.edu.cn/simple $pip install onnx-simplifier -i https://pypi.tuna.tsinghua.edu.cn/simple -
运行wenet自带的模型转换脚本, 确保wenet环境配置正确。
$python wenet/bin/export_onnx_gpu.py \\ --config opendla/train.yaml \\ --checkpoint opendla/final.pt \\ --cmvn_file opendla/global_cmvn \\ --output_onnx_dir opendla/ \\ --num_decoding_left_chunks -1 \\ --reverse_weight 0.3其中,
opendla即为从官网上下载的模型文件夹, 可自行命名。模型转换成功后, 输出的log信息中会打印:INFO:wenet/bin/export_onnx_gpu.py:export to onnx encoder succeed!INFO:wenet/bin/export_onnx_gpu.py:export to onnx decoder succeed! -
优化图结构
$python -m onnxsim opendla/encoder.onnx opendla/conformer_sim.onnx
此时已经可以转换出onnx, 但是还无法部署到到我们的平台, 需要对某些算子进行修改。
-
-
模型修改
-
修改原始代码, 将动长输入改成定长输入
-
wenet/transformer/encoder.py第152行处添加如下语句:xs_lens = torch.tensor([xs[:,:,0].bool().sum()]) -
wenet/bin/export_onnx_gpu.py中第69行-79行处的代码进行修改, 改动如下:-
原始代码
ctc_log_probs = self.ctc.log_softmax(encoder_out) encoder_out_lens = encoder_out_lens.int() beam_log_probs, beam_log_probs_idx = torch.topk(ctc_log_probs, self.beam_size, dim=2) return ( encoder_out, encoder_out_lens, ctc_log_probs beam_log_probs, beam_log_probs_idx, ) -
修改代码
ctc_log_probs = self.ctc.ctc_lo(encoder_out) return (ctc_log_probs)
-
-
wenet/bin/export_onnx_gpu.py中第746行-827行的代码进行修改, 改动如下:-
原始代码
def export_offline_encoder(model, configs, args, logger, encoder_onnx_path): bz = 32 seq_len = 100 beam_size = args.beam_size feature_size = configs["input_dim"] speech = torch.randn(bz, seq_len, feature_size, dtype=torch.float32) speech_lens = torch.randint(low=10, high=seq_len, size=(bz, ), dtype=torch.int32) encoder = Encoder(model.encoder, model.ctc, beam_size) encoder.eval() torch.onnx.export( encoder, (speech, speech_lens), encoder_onnx_path, export_params=True, opset_version=13, do_constant_folding=True, input_names=["speech", "speech_lengths"], output_names=[ "encoder_out", "encoder_out_lens", "probs" "beam_log_probs", "beam_log_probs_idx", ], dynamic_axes={ "speech": { 0: "B", 1: "T" }, "speech_lengths": { 0: "B" }, "encoder_out": { 0: "B", 1: "T_OUT" }, "encoder_out_lens": { 0: "B" }, "ctc_log_probs": { 0: "B", 1: "T_OUT" }, "beam_log_probs": { 0: "B", 1: "T_OUT" }, "beam_log_probs_idx": { 0: "B", 1: "T_OUT" }, }, verbose=False, ) with torch.no_grad(): o0,o1,o2,o3,o4 = F.log_softmax(encoder(speech, speech_lens), dim=2) providers = ["CUDAExecutionProvider"] ort_session = onnxruntime.InferenceSession(encoder_onnx_path, providers=providers) ort_inputs = { "speech": to_numpy(speech), "speech_lengths": to_numpy(speech_lens), } ort_outs = ort_session.run(None, ort_inputs) # check encoder output test(to_numpy([o0,o1,o2,o3,o4]), ort_outs) logger.info("export offline onnx encoder succeed!") onnx_config = { "beam_size": args.beam_size, "reverse_weight": args.reverse_weight, "ctc_weight": args.ctc_weight, "fp16": args.fp16, } return onnx_config -
改动代码
def export_offline_encoder(model, configs, args, logger, encoder_onnx_path): bz = 1 seq_len = 400 beam_size = args.beam_size feature_size = configs["input_dim"] speech = torch.randn(bz, seq_len, feature_size, dtype=torch.float32) speech_lens = torch.randint(low=10, high=seq_len, size=(bz, ), dtype=torch.int32) encoder = Encoder(model.encoder, model.ctc, beam_size) encoder.eval() torch.onnx.export( encoder, (speech, speech_lens), encoder_onnx_path, export_params=True, opset_version=13, do_constant_folding=True, input_names=["speech", "speech_lengths"], output_names=["probs"], verbose=False, ) with torch.no_grad(): o0 = F.log_softmax(encoder(speech, speech_lens), dim=2) providers = ["CPUExecutionProvider"] ort_session = onnxruntime.InferenceSession(encoder_onnx_path, providers=providers) ort_inputs = { "speech": to_numpy(speech), # "speech_lengths": to_numpy(speech_lens), } ort_outs = F.log_softmax(torch.tensor(ort_session.run(None, ort_inputs)[0]), dim=2) # check encoder output test(o0, ort_outs) logger.info("export offline onnx encoder succeed!") onnx_config = { "beam_size": args.beam_size, "reverse_weight": args.reverse_weight, "ctc_weight": args.ctc_weight, "fp16": args.fp16, } return onnx_config
-
-
修改完成后, 再执行模型导出步骤, 即可生成可以部署的conformer.onnx模型。
-
2.2 离线模型转换¶
2.2.1 预&后处理说明¶
-
预处理
语音输入到模型之前, 需要将语音wav转换为fbank。转换成功的conformer_sim.onnx模型输入信息如下图所示, 要求输入的fbank长度为 (1, 400, 80)。其中, 400为时间序列长度, 80为通道数大小。
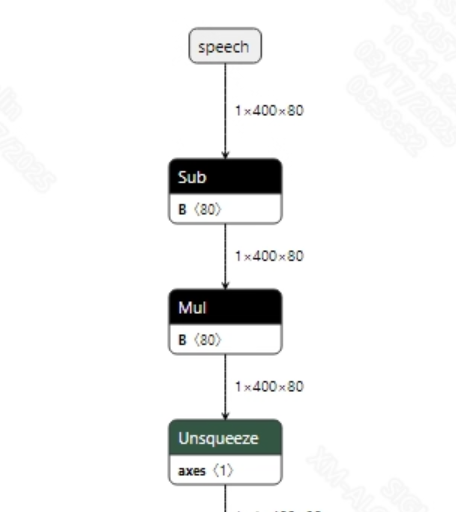
-
后处理
转换成功的conformer_sim.onnx模型输出信息如下图所示, 输出维度为(1, 99, 5538), 其中99是输出的文本长度, 5538是类别。获取到输出的特征后, 需要先经过log_softmax处理, 然后采用gready search的方式对输出特征进行解码, 才能转换出文本序列。
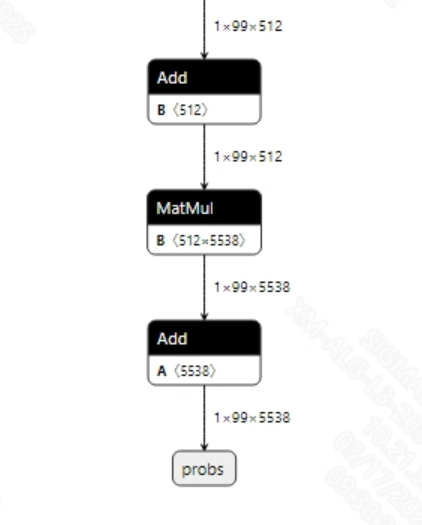
2.2.2 offline模型转换流程¶
注意:1)OpenDLAModel对应的是压缩包image-dev_model_convert.tar解压之后的smodel文件。2)转换命令需要在docker环境下运行, 请先根据Docker开发环境教程, 加载SGS Docker环境。
-
拷贝onnx模型到转换代码目录
$cp opendla/conformer_sim.onnx OpenDLAModel/asr/conformer/onnx -
转换命令
$cd IPU_SDK_Release/docker $bash run_docker.sh #进入到docker环境下的OpenDLAModel目录 $cd /work/SGS_XXX/OpenDLAModel $bash convert.sh -a asr/conformer -c config/asr_conformer.cfg -p SGS_IPU_Toolchain(绝对路径) -s false -
最终生成的模型地址
output/${chip}_${时间}/conformer_sim.img output/${chip}_${时间}/conformer_sim_fixed.sim output/${chip}_${时间}/conformer_sim_float.img
2.2.3 关键脚本参数解析¶
- input_config.ini
[INPUT_CONFIG]
inputs=speech; #onnx 输入节点名称, 如果有多个需以“,”隔开;
input_formats=RAWDATA_F32_NHWC; #板端输入格式, 可以根据onnx的输入格式选择, 例如float:RAWDATA_F32_NHWC, int32:RAWDATA_S16_NHWC;
quantizations=TRUE; #打开输入量化, 不需要修改;
[OUTPUT_CONFIG]
outputs=probs; #onnx 输出节点名称, 如果有多个需以“,”隔开;
dequantizations=TRUE; #是否开启反量化, 根据实际需求填写, 建议为TRUE。设为False, 输出为int16; 设为True, 输出为float32
[OPTIMIZE_CONFIG]
optimize_layernorm_precision=TRUE;
- asr_conformer.cfg
[COMFORMER]
CHIP_LIST=pcupid #平台名称, 必须和板端平台一致, 否则模型无法运行
Model_LIST=conformer_sim #输入onnx模型名称
INPUT_SIZE_LIST=0 #模型输入分辨率
INPUT_INI_LIST=input_config.ini #配置文件
CLASS_NUM_LIST=0 #填0即可
SAVE_NAME_LIST=conformer_sim.img #输出模型名称, 可自行修改
QUANT_DATA_PATH=image_list.txt #量化数据路径
2.3 模型仿真¶
-
获取float/fixed/offline模型输出
$bash convert.sh -a asr/conformer -c configs/asr_conformer.cfg -p SGS_IPU_Toolchain(绝对路径) -s true执行上述命令后, 会默认将
float模型的输出tensor保存到asr/conformer/log/output路径下的txt文件中。此外, 在asr/conformer/convert.sh脚本中也提供了fixed和offline的仿真示例, 用户在运行时可以通过打开注释代码块, 分别获取fixed和offline模型输出。 -
模型精度对比
在保证输入和上述模型相同的情况下, 进入2.1章节搭建好的环境, 在
wenet/wenet/bin/export_onnx_gpu.py脚本的export_offline_encoder函数中添加打印:print(encoder(speech, speech_lens))即可获取pytorch模型对应节点的输出tensor, 进而和float、fixed、offline模型进行对比。此外需要特别注意的是, 原始模型的输出格式是
NCHW, 而float/fixed/offline模型输出的格式是NHWC。
3 板端部署¶
3.1 程序编译¶
示例程序编译之前需要先根据板子(nand/nor/emmc, ddr型号等)选择deconfig进行sdk整包编译, 具体可以参考alkaid sdk sigdoc《开发环境搭建》文档。
-
编译板端conformer示例。
$cd sdk/verify/opendla $make clean && make source/asr/conformer -j8 -
最终生成的可执行文件地址
sdk/verify/opendla/out/${AARCH}/app/prog_asr_conformer
3.2 运行文件¶
运行程序时, 需要先将以下几个文件拷贝到板端
- prog_asr_conformer
- BAC009S0764W0121.wav
- units_asr_punc_lm.txt
- conformer_400x80.img
3.3 运行说明¶
-
Usage:
./prog_asr_conformer -i wav -m model -d txt(执行文件使用命令) -
Required Input:
- wav: 音频路径
- model:需要测试的offline模型路径
- txt:字典
-
Typical Output:
./prog_asr_conformer -i resource/BAC009S0764W0121.wav -m models/conformer_400x80.img -d resource/units_asr_punc_lm.txt input path: resource/BAC009S0764W0121.wav model path: models/conformer_400x80.img dict path: resource/units_client [907] connected, module:ipu asr_punc_lm.txt num_frames: 418, sizeof(input_buf): 128000 model invoke time: 330.710000 ms load dict... vocabulary size: 5538 decode result... 甚至出现交易几乎停滞的情况 ------shutdown IPU0------ client [907] disconnected, module:ipu