PP-OCR
1 概述¶
1.1 背景介绍¶
PP-OCR是百度开源的中英文OCR系统, 具有超轻量、高精度、易用性等特点, 是目前业界主流的开源OCR系统之一。如下图所示, PP-OCR主要由文本检测、方向分类、文本识别三部分组成:
PP-OCR社区持续在更新中, 我们采用的是PP-OCRv4版本, 详情可参考PP-OCR官方说明:
https://github.com/PaddlePaddle/PaddleOCR/blob/v2.8.1/doc/doc_ch/PP-OCRv4_introduction.md
由于方向分类并不影响最终的文本识别结果, 因此我们仅选择PP-OCR系统中的文本检测和文本识别模型进行部署, 模型下载地址如下: ppocrv4_det ppocrv4_rec
1.2 使用说明¶
Linux SDK-alkaid中默认带了已经预先转换好的离线模型及板端示例, 相关文件路径如下:
-
板端示例程序路径
Linux_SDK/sdk/verify/opendla/source/ocr/ppocr -
板端离线模型路径
Linux_SDK/project/board/${chip}/dla_file/ipu_open_models/ocr/ppocr_det_640x640.img Linux_SDK/project/board/${chip}/dla_file/ipu_open_models/ocr/ppocr_rec_320x48.img -
板端测试图像路径
Linux_SDK/sdk/verify/opendla/source/resource/lite_demo.png
如果用户不需要转换模型可直接跳转至第3章节。
2 模型转换¶
2.1 onnx模型转换¶
-
python环境搭建
$conda create --name paddle_env python=3.8 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ $conda activate paddle_env $pip install --upgrade pip #如果您的机器安装的是CUDA9或CUDA10, 请运行以下命令安装 $python -m pip install paddlepaddle-gpu==2.0.0 -i https://mirror.baidu.com/pypi/simple $git clone https://github.com/PaddlePaddle/PaddleOCR $cd PaddleOCR $pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple注意:这里提供的python环境搭建, 仅作为参考示例, 具体搭建过程请参考官方源码运行教程:
https://github.com/PaddlePaddle/PaddleOCR/blob/v2.8.1/doc/doc_ch/environment.md https://github.com/PaddlePaddle/PaddleOCR/blob/v2.8.1/doc/doc_ch/installation.md -
模型测试
- 运行模型测试脚本, 确保paddle_env环境配置正确。
$python3 tools/infer/predict_system.py --image_dir="./doc/imgs/00018069.jpg" --det_model_dir="./ch_PP-OCRv4_det_infer/" --rec_model_dir="./ch_PP-OCRv4_rec_infer/" --use_angle_cls=false --use_gpu="1"
具体可参考PP-COR官方测试文档
https://github.com/PaddlePaddle/PaddleOCR/blob/v2.8.1/doc/doc_ch/inference_ppocr.md - 运行模型测试脚本, 确保paddle_env环境配置正确。
-
模型导出
-
运行模型转换脚本
$paddle2onnx --model_dir ./ch_PP-OCRv4_det_infer \ --model_filename inference.pdmodel \ --params_filename inference.pdiparams \ --save_file ./opendla/det_onnx/model.onnx \ --opset_version 11 \ --enable_onnx_checker True $paddle2onnx --model_dir ./ch_PP-OCRv4_rec_infer \ --model_filename inference.pdmodel \ --params_filename inference.pdiparams \ --save_file ./opendla/rec_onnx/model.onnx \ --opset_version 11 \ --enable_onnx_checker True -
优化图结构
$python3 -m paddle2onnx.optimize ./opendla/det_onnx/model.onnx ./opendla/det_onnx/ppocr_det_fix.onnx $python3 -m onnxsim ./opendla/rec_onnx/model.onnx ./opendla/rec_onnx/model_sim.onnx $python3 -m paddle2onnx.optimize ./opendla/rec_onnx/model_sim.onnx ./opendla/rec_onnx/ppocr_rec_fix.onnx
-
2.2 离线模型转换¶
2.2.1 预&后处理说明¶
-
预处理
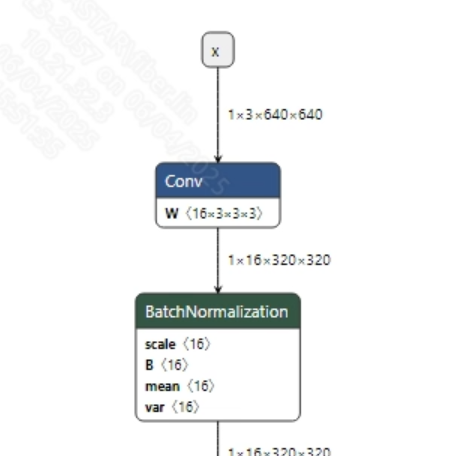
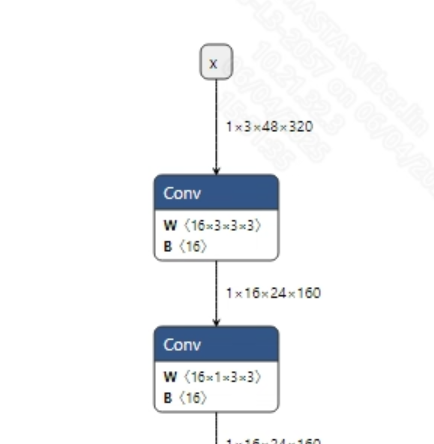
转换成功的ppocr_det_fix.onnx和ppocr_rec_fix.onnx模型输入信息如下图所示, 输入图像的尺寸分别为 (1, 3, 640, 640)和(1, 3, 48, 320)。 此外需要对输入的像素值进行归一化, 其中, 检测模型需要归一化到[0, 1]之间, 文本识别模型需要归一化到[-1, 1]之间。
-
后处理
ppocr_det_fix.onnx模型输出信息如下图所示, 该输出表示图像上每个像素点为文本的概率, 需要再经过阈值过滤、二值图转换、外接矩形等操作, 最终才能输出最终文本的坐标框, 详情可参考db_postprocess, 模型的输出维度如下图所示。

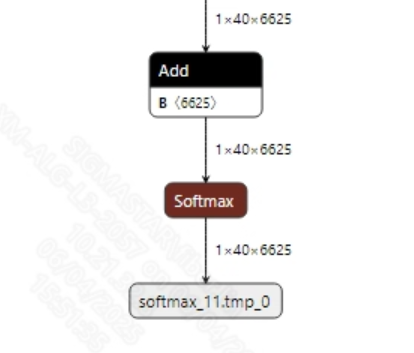
ppocr_rec_fix.onnx模型输出信息如下图所示, 获取到模型的输出数据后调用ctc解码即可得到最终的结果
2.2.2 offline模型转换流程¶
注意:1)OpenDLAModel对应的是压缩包image-dev_model_convert.tar解压之后的smodel文件。2)转换命令需要在docker环境下运行, 请先根据Docker开发环境教程, 加载SGS Docker环境。
-
拷贝onnx模型到转换代码目录
$cp opendla/det_onnx/ppocr_det_fix.onnx OpenDLAModel/ocr/ppocr/onnx $cp opendla/rec_onnx/ppocr_rec_fix.onnx OpenDLAModel/ocr/ppocr/onnx -
转换命令
$cd IPU_SDK_Release/docker $bash run_docker.sh #进入到docker环境下的OpenDLAModel目录 $cd /work/SGS_XXX/OpenDLAModel $bash convert.sh -a ocr/ppocr -c config/ocr_ppocr.cfg -p SGS_IPU_Toolchain(绝对路径) -s false -
最终生成的模型地址
output/${chip}_${时间}/ppocr_det_640x640.img output/${chip}_${时间}/ppocr_det_640x640_fixed.sim output/${chip}_${时间}/ppocr_det_640x640_float.sim output/${chip}_${时间}/ppocr_rec_320x48.img output/${chip}_${时间}/ppocr_rec_320x48_fixed.sim output/${chip}_${时间}/ppocr_rec_320x48_float.sim
2.2.3 关键脚本参数解析¶
- det_input_config.ini
[INPUT_CONFIG]
inputs = x; #onnx 输入节点名称, 如果有多个需以“,”隔开;
training_input_formats = RGB; #模型训练时的输入格式, 通常都是RGB;
input_formats = BGRA; #板端输入格式, 可以根据情况选择BGRA或者YUV_NV12;
quantizations = TRUE; #打开输入量化, 不需要修改;
mean_red = 123.48; #均值, 跟模型预处理相关, 根据实际情况配置;
mean_green = 116.28; #均值, 跟模型预处理相关, 根据实际情况配置;
mean_blue = 103.53; #均值, 跟模型预处理相关, 根据实际情况配置;
std_value = 58.395:57.12:57.375; #方差, 跟模型预处理相关, 根据实际情况配置;
[OUTPUT_CONFIG]
outputs = sigmoid_0.tmp_0; #onnx 输出节点名称, 如果有多个需以“,”隔开;
dequantizations = FALSE; #是否开启反量化, 根据实际需求填写, 建议为TRUE。设为False, 输出为int16; 设为True, 输出为float32
- rec_input_config.ini
[INPUT_CONFIG]
inputs = x; #onnx 输入节点名称, 如果有多个需以“,”隔开;
training_input_formats = RGB; #模型训练时的输入格式, 通常都是RGB;
input_formats = BGRA; #板端输入格式, 可以根据情况选择BGRA或者YUV_NV12;
quantizations = TRUE; #打开输入量化, 不需要修改;
mean_red = 127.5; #均值, 跟模型预处理相关, 根据实际情况配置;
mean_green = 127.5; #均值, 跟模型预处理相关, 根据实际情况配置;
mean_blue = 127.5; #均值, 跟模型预处理相关, 根据实际情况配置;
std_value = 127.5; #方差, 跟模型预处理相关, 根据实际情况配置;
[OUTPUT_CONFIG]
outputs = softmax_11.tmp_0; #onnx 输出节点名称, 如果有多个需以“,”隔开;
dequantizations = FALSE; #是否开启反量化, 根据实际需求填写, 建议为TRUE。设为False, 输出为int16; 设为True, 输出为float32
- ocr_ppocr.cfg
[PPOCR]
CHIP_LIST=pcupid #平台名称, 必须和板端平台一致, 否则模型无法运行
Model_LIST=ppocr_det_fix,ppocr_rec_fix #输入onnx模型名称
INPUT_SIZE_LIST=0,0 #模型输入分辨率,这边可以不指定
INPUT_INI_LIST=det_input_config.ini,det_input_config.ini #配置文件
CLASS_NUM_LIST=0 ,0 #填0即可
SAVE_NAME_LIST=ppocr_det_640x640.img,ppocr_rec_320x48.img #输出模型名称
QUANT_DATA_PATH=quant_data_det,quant_data_rec #量化图片路径
2.3 模型仿真¶
-
获取float/fixed/offline模型输出
$bash convert.sh -a ocr/ppocr -c config/ocr_ppocr.cfg -p SGS_IPU_Toolchain(绝对路径) -s true执行上述命令后, 会默认将
float模型的输出tensor保存到ocr/ppocr/log/output路径下的txt文件中。此外, 在ocr/ppocr/convert.sh脚本中也提供了fixed和offline的仿真示例, 用户在运行时可以通过打开注释代码块, 分别获取fixed和offline模型输出。 -
模型精度对比
在保证输入和上述模型相同的情况下, 进入2.1章节搭建好的环境, 对于检测模型, 可以在
PaddleOCR/tools/infer/predict_det.py文件第273行处添加打印:print(outputs)对于文本识别模型可以在
PaddleOCR/tools/infer/predict_rec.py文件第825行处添加打印:print(preds)获取pytorch模型对应节点的输出tensor, 进而和float、fixed、offline模型进行对比。此外需要特别注意的是, 原始模型的输出格式是
NCHW, 而float/fixed/offline模型输出的格式是NHWC。
3 板端部署¶
3.1 程序编译¶
示例程序编译之前需要先根据板子(nand/nor/emmc, ddr型号等)选择deconfig进行sdk整包编译, 具体可以参考alkaid sdk sigdoc《开发环境搭建》文档。
-
编译板端ppocr示例。
$cd sdk/verify/opendla $make clean && make source/ocr/ppocr -j8 -
最终生成的可执行文件地址
sdk/verify/opendla/out/${AARCH}/app/prog_ocr_ppocr
3.2 运行文件¶
运行程序时, 需要先将以下几个文件拷贝到板端
- prog_ocr_ppocr
- lite_demo.png
- ppocr_keys_v1.txt
- ppocr_det_640x640.img, ppocr_rec_320x48.img
3.3 运行说明¶
-
Usage:
./prog_ocr_ppocr det_model rec_model image dict(执行文件使用命令) -
Required Input:
- det_model: 文本检测模型
- det_model: 文本识别模型
- image: 图像文件夹/单张图像路径
- dict: 字典
-
Typical output:
./prog_ocr_ppocr models/ppocr_det_640x640.img models/ppocr_rec_320x48.img resource/lite_demo.png resource/ppocr_keys_v1.txt client [758] connected, module:ipu found 1 images! [0] processing resource/lite_demo.png... fillbuffer processing... net input width: 640, net input height: 640 花费了0.457335秒, 0.999969, 0.997668, 0.999969, 发足够的滋养, 0.999969, 14, 0.999969, 即时持久改善头发光泽的效果, 给干燥的头, 0.999969, 0.990198, 0.999969, 13, 0.999969, 【主要功能】:可紧致头发磷层, 从而达到, 0.999969, 0.994448, 0.999969, 12, 0.999969, 0.972573, 0.999969, (成品包材), 0.999969, 11, 0.999969, 0.925898, 0.999969, 糖、椰油酰胺丙基甜菜碱、泛醒, 0.999969, 10, 0.999969, 【主要成分】:鲸蜡硬脂醇、燕麦B-葡聚, 0.940574, 0.961928, 0.999969, 9, 0.799982, 【适用人群】:适合所有肤质, 0.999969, 0.995842, 0.999969, 8, 0.999969, 0.996577, 0.999969, 【净含量】:220ml, 0.969673, 7, 0.444441, 【产品编号】:YM-X-30110.96899, 0.999969, 6, 0.999969, 【品名】:纯臻营养护发素, 0.999969, 0.995007, 0.999969, 5, 0.999969, 0.985133, 0.999969, 【品牌】:代加工方式/OEMODM, 0.988205, 4, 0.999969, 每瓶22元, 1000瓶起订), 0.985685, 0.993976, 0.999969, 3, 0.999969, (45元/每公斤, 100公斤起订), 0.988205, 0.97417, 0.999969, 2, 0.999969, 0.992728, 0.999969, 产品信息/参数, 0.999969, 1, 0.999969, 纯臻营养护发素0.993604, 0.986637, Thede, 0.746648, invoke time: 54.502000 ms postprocess time: 58.893000 ms text recognition time: 2718.544000 ms ------shutdown IPU0------ client [758] disconnected, module:ipu