EAT
1 概述¶
1.1 背景介绍¶
本次开源的声音事件检测算法来源于Aibaba开源的语音算法仓库, 具有轻量级、稳定性高等特点。但由于该github仓库仅开源代码, 未开源模型, 因此模型需要用户自行训练。有关模型的详细信息可访问:
https://github.com/Alibaba-MIIL/AudioClassfication
我们release的模型是在ESC-50数据集进行训练的, 训练指令为:
python trainer.py \
--max_lr 3e-4 \
--run_name r1 \
--emb_dim 128 \
--dataset esc50 \
--seq_len 114688 \
--mix_ratio 1 \
--epoch_mix 12 \
--mix_loss bce \
--batch_size 128 \
--n_epochs 3500 \
--ds_factors 4 4 4 4 \
--amp \
--save_path outputs
ESC-50数据集下载地址为:
https://github.com/karoldvl/ESC-50/archive/master.zip
1.2 使用说明¶
Linux SDK-alkaid中默认带了已经预先转换好的离线模型及板端示例, 相关文件路径如下:
-
板端示例程序路径
Linux_SDK/sdk/verify/opendla/source/sed -
板端离线模型路径
Linux_SDK/project/board/${chip}/dla_file/ipu_open_models/eat.img -
板端测试音频路径
Linux_SDK/sdk/verify/opendla/source/resource/1-137-A-32_22.05k.wav
如果用户不需要转换模型可直接跳转至第3章节。
2 模型转换¶
2.1 onnx模型转换¶
-
python环境搭建
$conda create -n sed python==3.10 $conda activate sed $git clone https://github.com/Alibaba-MIIL/AudioClassfication.git $cd AudioClassfication $conda install pytorch=1.12.1 torchaudio=0.12.1 cudatoolkit=11.3 -c pytorch -c conda-forge注意:这里提供的python环境搭建, 仅作为参考示例, 具体搭建过程请参考官方源码运行教程:
https://github.com/Alibaba-MIIL/AudioClassfication/blob/main/README.md -
模型测试
-
运行模型测试脚本, 确保sed环境配置正确。
$python inference.py --f_res outputs/r1其中, outputs/r1为模型存放路径
-
-
模型导出
-
安装依赖包
$pip install onnx -i https://pypi.tuna.tsinghua.edu.cn/simple $pip install onnx-simplifier -i https://pypi.tuna.tsinghua.edu.cn/simple $pip install onnxruntime -i https://pypi.tuna.tsinghua.edu.cn/simple -
编写模型转换脚本
export_onnx.pyimport torch from torch.utils.data import DataLoader from pathlib import Path import argparse import yaml from utils.helper_funcs import accuracy, count_parameters, mAP, measure_inference_time import numpy as np import torch.nn.functional as F import os import onnx import onnxsim import onnxruntime device = "cpu" def parse_args(): parser = argparse.ArgumentParser() parser.add_argument("--f_res", default=None, type=Path) args = parser.parse_args() return args def run(): args = parse_args() f_res = args.f_res # add_noise = args.add_noise with (args.f_res / Path("args.yml")).open() as f: args = yaml.load(f, Loader=yaml.Loader) try: args = vars(args) except: if 'net' in args.keys(): del args['net'] args_orig = args args = {} for k, v in args_orig.items(): if isinstance(v, dict): for kk, vv in v.items(): args[kk] = vv else: args[k] = v args['f_res'] = f_res # args['add_noise'] = add_noise with open(args['f_res'] / "args.yml", "w") as f: yaml.dump(args, f) print(args) ####################### # Load PyTorch Models # ####################### from modules.soundnet import SoundNetRaw as SoundNet ds_fac = np.prod(np.array(args['ds_factors'])) * 4 net = SoundNet(nf=args['nf'], dim_feedforward=args['dim_feedforward'], clip_length=args['seq_len'] // ds_fac, embed_dim=args['emb_dim'], n_layers=args['n_layers'], nhead=args['n_head'], n_classes=args['n_classes'], factors=args['ds_factors'], ) print('***********************************************') print("#params: {}M".format(count_parameters(net)/1e6)) if torch.cuda.is_available() and device == torch.device("cuda"): t_b1 = measure_inference_time(net, torch.randn(1, 1, args['seq_len']))[0] print('inference time batch=1: {:.2f}[ms]'.format(t_b1)) # t_b32 = measure_inference_time(net, torch.randn(32, 1, args['seq_len']))[0] # print('inference time batch=32: {:.2f}[ms]'.format(t_b32)) print('***********************************************') if (f_res / Path("chkpnt.pt")).is_file(): chkpnt = torch.load(f_res / "chkpnt.pt", map_location=torch.device(device)) model = chkpnt['model_dict'] else: raise ValueError if 'use_dp' in args.keys() and args['use_dp']: from collections import OrderedDict state_dict = OrderedDict() for k, v in model.items(): name = k.replace('module.', '') state_dict[name] = v net.load_state_dict(state_dict, strict=True) else: net.load_state_dict(model, strict=True) net.to(device) if torch.cuda.device_count() > 1: from utils.helper_funcs import parse_gpu_ids args['gpu_ids'] = [i for i in range(torch.cuda.device_count())] net = torch.nn.DataParallel(net, device_ids=args['gpu_ids']) net.to('cuda:0') net.eval() x = torch.randn((1,1,114688)).to(device) torch_out = net(x) print(torch_out) f = 'outputs/r1/eat.onnx' # filename torch.onnx.export(net, x, f, verbose=False, opset_version=13, input_names=['images'], output_names=['output']) model_onnx = onnx.load(f) # load onnx model onnx.checker.check_model(model_onnx) # check onnx model ort_session = onnxruntime.InferenceSession(f,providers=['CPUExecutionProvider']) def to_numpy(tensor): return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy() # compute ONNX Runtime output prediction ort_inputs = {ort_session.get_inputs()[0].name: to_numpy(x)} ort_outs = ort_session.run(None, ort_inputs) print(ort_outs) model_onnx, check = onnxsim.simplify(model_onnx) onnx.save(model_onnx, f.replace('eat','eat_sim')) if __name__ == '__main__': run() -
运行模型转换脚本
export_onnx.py。python export_onnx.py --f_res output_r1
-
2.2 离线模型转换¶
2.2.1 预&后处理说明¶
- 预处理 语音输入到模型之前, 通常需要调用torchaudio.load接口将音频数据转换为适合模型输入的张量, 然后再进行补0(padding)操作, 固定的输入长度; 最后再进行归一化处理。模型输入信息如下所示:
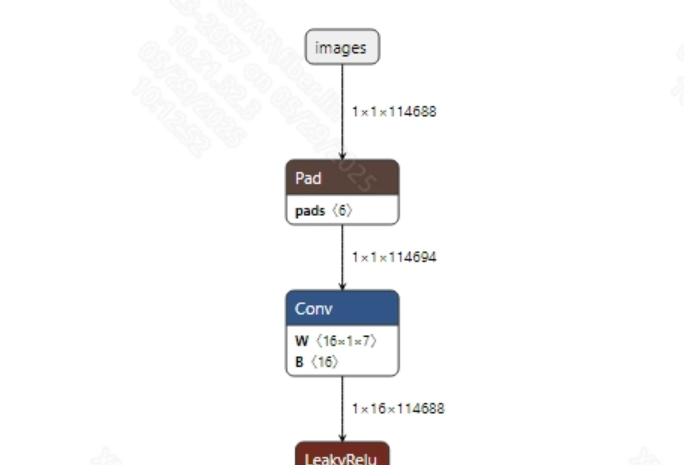
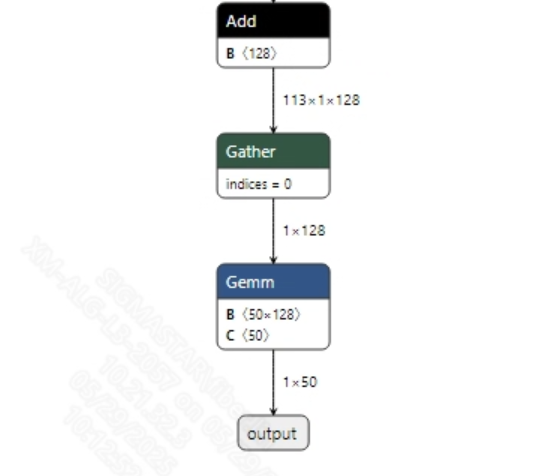
- 后处理 声音分类模型没有后处理操作, 获取到模型输出信息后, 通过softmax以及argmax处理后就可以得到最终结果。模型输出信息如下所示:
2.2.2 offline模型转换流程¶
注意:1)OpenDLAModel对应的是压缩包image-dev_model_convert.tar解压之后的smodel文件。2)转换命令需要在docker环境下运行, 请先根据Docker开发环境教程, 加载SGS Docker环境。
-
拷贝onnx模型到转换代码目录
$cp outputs/r1/eat_sim.onnx OpenDLAModel/sed/eat/onnx -
转换命令
$cd IPU_SDK_Release/docker $bash run_docker.sh #进入到docker环境下的OpenDLAModel目录 $cd /work/SGS_XXX/OpenDLAModel $bash convert.sh -a sed/eat -c config/sed_eat.cfg -p SGS_IPU_Toolchain(绝对路径) -s false -
最终生成的模型地址
output/${chip}_${时间}/eat.img output/${chip}_${时间}/eat_fixed.sim output/${chip}_${时间}/eat_float.sim
2.2.3 关键脚本参数解析¶
- input_config.ini
[INPUT_CONFIG]
inputs=images; #onnx 输入节点名称, 如果有多个需以“,”隔开;
training_input_formats=RAWDATA_F32_NHWC; #模型训练数据的格式
input_formats=RAWDATA_F32_NHWC; #板端输入格式, 可以根据onnx的输入格式选择, 例如float:RAWDATA_F32_NHWC, int32:RAWDATA_S16_NHWC;
quantizations=TRUE; #打开输入量化, 不需要修改;
[OUTPUT_CONFIG]
outputs=output; #onnx 输出节点名称, 如果有多个需以“,”隔开;
dequantizations=FALSE; #是否开启反量化, 根据实际需求填写, 建议为TRUE。设为False, 输出为int16; 设为True, 输出为float32
[CONV_CONFIG]
#input_format="ALL_INT16";
- sed_eat.cfg
[EAT]
CHIP_LIST=pcupid #平台名称, 必须和板端平台一致, 否则模型无法运行
Model_LIST=eat_sim #输入onnx模型名称
INPUT_SIZE_LIST=0 #模型输入分辨率
INPUT_INI_LIST=input_config.ini #配置文件
CLASS_NUM_LIST=0 #填0即可
SAVE_NAME_LIST=eat.img #输出模型名称
QUANT_DATA_PATH=quant_data #量化数据路径
2.3 模型仿真¶
-
获取float/fixed/offline模型输出
$bash convert.sh -a sed/eat -c config/sed_eat.cfg -p SGS_IPU_Toolchain(绝对路径) -s true执行上述命令后, 会默认将
float模型的输出tensor保存到sed/eat/log/output路径下的txt文件中。此外, 在sed/eat/convert.sh脚本中也提供了fixed和offline的仿真示例, 用户在运行时可以通过打开注释代码块, 分别获取fixed和offline模型输出。 -
模型精度对比
在保证输入和上述模型相同的情况下, 进入2.1章节搭建好的环境, 在在
AudioClassfication/inference.py文件中第157行处添加打印:print(pred)即可获取pytorch模型对应节点的输出tensor, 进而和float、fixed、offline模型进行对比。此外需要特别注意的是, 原始模型的输出格式是
NCHW, 而float/fixed/offline模型输出的格式是NHWC。
3 板端部署¶
3.1 程序编译¶
示例程序编译之前需要先根据板子(nand/nor/emmc, ddr型号等)选择deconfig进行sdk整包编译, 具体可以参考alkaid sdk sigdoc《开发环境搭建》文档。
-
编译板端eat示例。
$cd sdk/verify/opendla $make clean && make source/sed/eat -j8 -
最终生成的可执行文件地址
sdk/verify/opendla/out/${AARCH}/app/prog_sed_eat
3.2 运行文件¶
运行程序时, 需要先将以下几个文件拷贝到板端
- prog_sed_eat
- 1-137-A-32_22.05k.wav
- eat.img
3.3 运行说明¶
-
Usage:
./prog_sed_eat -i wav -m model(执行文件使用命令) -
Required Input:
- i: 音频文件
- m: 模型文件
-
Typical Output:
./prog_sed_eat -i 1-137-A-32_22.05k.wav -m models/eat.img inputs: 1-137-A-32_22.05k.wav model path: models/eat.img threshold: 0.500000 client [836] connected, module:ipu unknown element format 5 found 1 images! the input image: ./1-137-A-32_22.05k.wav model invoke time: 57.121000 ms post process time: 0.181000 ms class id: 32