7. IPU Toolchain 算子支持
1. Caffe支持算子¶
| 算子 | 备注 |
|---|---|
| ArgMax | only support top 1 |
| Axpy | |
| BatchNorm | |
| Concat | 最大1024个tensor concat |
| Convolution | 限制条件:All tensor size < 2^31 若kernel size 为 do*h*w*di 则h * w < 64 group为1时:转换成Depthwise Convolution; group为C时:转换为Convolution; group为 (1, C) 时:拆解成GroupConv round(di/16)*round(do/16) < 512 * 1024 |
| ConvolutionDepthwise | 原生支持Kernel_size为3*3,6*6,9*9,其余情况转换成Convolution处理限制条件:Pad范围:[0, 1] |
| CReLU | 输入<=4维 |
| ContinuationIndicator | |
| Crop | |
| Deconvolution | All tensor size < 2^31 若kernel size 为 do*h*w*di,h * w < 64 round(di/16)*round(do/16) < 512 * 1024 |
| Dropout | |
| Eltwise | 其中PROD和SUM,对于输入的两个tensor,当为4维向量时,满足下面条件 1. NCHW ,const 2. NCHW ,C维向量 3. NCHW ,NCHW 当为5维向量时,满足 1. NCDHW ,const 2. NCDHW ,NCDHW |
| Flatten | |
| InnerProduct | 若weight size do*di round(di/16)*round(do/16) < 512 * 1024 |
| Permute | |
| Pooling | 若kernel size为h*w 1.AVGPooling (1).FilterW <= 255,FilterH <= 255, (2).AvePooling_U8:FilterMax(FilterW*FilterH) = 12288, (3).AvePooling_S16:FilterMax(FilterW*FilterH) = 12288 2.MaxPooling: 需FilterW <= 255,且FilterMax(FilterW*FilterH) = 6029312 |
| PriorBox | |
| Power | 仅支持指数为正整数 |
| Reshape | |
| Reverse | |
| ROIPooling | ROIPooling的rois输入维度为(N×5),当后段网络全部是InnerProduct时,N才可以设置大于1,如果后段网络中有卷积时,N仅可以设置为1,第二段网络需要循环执行N次。使用方法和限制详见下方Please Note。 |
| ReLU | 输入<=4维 |
| PRuLU | 输入<=4维 |
| Sigmoid | |
| Slice | |
| Scale | 对于输入的两个tensor,shape满足下面条件 1. 4维向量,NCHW 2. NCHW ,const 3. NCHW ,C维向量 4. NCHW ,NCHW 当为5维向量时,满足 1. NCDHW ,const 2. NCDHW ,NCDHW |
| Softmax | 如需对指定维度进行运算,将要计算的维度转置到最后的维度(最内维度),最大支持32*512=16384 |
| Splite | |
| ShuffleChannel | |
| Tanh | 输入<=4维 |
| Threshold | 只支持4维输入 |
| Tile | |
| Upsample | Upsample算子在caffe中没有,可以手动将Deconvolution修改成Upsample 只支持4维输入 Only support same scale on H and W |
| Reorg | 只支持stride = 2 |
| LSTM | 支持单向,双向 |
Please Note:
-
Upsample算子在prototxt中这样描述:
scale参数与Deconvolution的Stride含义相同。但需注意Upsample相当于权重全为1的Deconvolution算子。layer { bottom: "layer85-conv" top: "layer86-upsample" name: "layer86-upsample" type: "Upsample" upsample_param { scale: 2 } } -
ROIPooling算子在prototxt中这样描述:
Roi_pooling_param仅支持pooled_w,pooled_h和spatial_scale。Float模型的rois输入为rpn层输出的坐标,Fixed和Offline模型的rois输入为rpn层输出坐标乘spatial_scale值后再量化到int16后送入模型。layer { name: "roi_pool5" type: "ROIPooling" bottom: "conv5_3" bottom: "rois" top: "pool5" roi_pooling_param { pooled_w: 7 pooled_h: 7 spatial_scale: 0.0625 } }
2. TensorFlow支持算子¶
| 算子 | 备注 |
|---|---|
| Convolution | 限制条件:Kernel_size:H * W < 64 |
| DepthwiseConv2dNative | 原生支持Kernel_size为3*3,6*6,9*9,其余情况转换成Convolution处理 |
| FullyConnected | |
| Max pooling | |
| Average Pooling | |
| ReLU | |
| PReLU | |
| ReLU6 | |
| LeakyReLU | |
| Sigmoid | |
| Less | |
| Log | |
| Greater | |
| GreaterEqual | |
| Equal | |
| Add | |
| Sub | |
| Mul | |
| RealDiv | 仅支持第二个操作数为常量Tensor |
| FloorDiv | 仅支持第二个操作数为常量Tensor |
| Maximum | |
| Minimum | |
| Mean | |
| Max | |
| Sqrt | |
| Sin | |
| Cos | |
| Rsqrt | |
| Round | |
| Softmax | 如需对指定维度进行运算,将要计算的维度转置到最后的维度(最内维度) |
| FusedBatchNorm | |
| Exp | |
| Align | |
| ConcatV2 | |
| Fill | |
| Gather | 仅支持第二个操作数indices为常量Tensor |
| GatherV2 | |
| Pack | |
| Pad | |
| SpaceToBatchND | |
| BatchToSpaceND | |
| Zeroslike | |
| Split | |
| Slice | |
| Unpack | |
| Tile | |
| Reshape | |
| Transpose | |
| Resize_bilinear | |
| Resize_NearestNeighbor | |
| Batch_matmul | |
| TopKV2 | |
| Tanh | |
| Concatenation | |
| Argmax | |
| Logistic | |
| TransposeConv | |
| Square | |
| StrideSlice | |
| Abs | |
| Sum | |
| Cast |
3. Onnx支持算子¶
| 算子 | 备注 |
|---|---|
| Abs | Unlimited |
| Add | Unlimited |
| And | Unlimited |
| ArgMax | axis: Unlimited keepdims: Unlimited select_last_index: Can only be set to 0 |
| ArgMin | axis: Unlimited keepdims: Unlimited select_last_index: Can only be set to 0 |
| Atan | Unlimited |
| AveragePool | auto_pad: Supported, SAME_UPPER, SAME_LOWER or VALID ceil_mode: Supported kernel_shape: If kernel_shape is h*w, it must meet FilterW <= 255, FilterH <= 255 pads: Supports two dimensions, both [0,255] strides: Supports two dimensions, both [0,255] count_include_pad: Unlimited dilation: Only supports 1 If KernelW == InputW and pad_W is 0, then there are no [0, 255] restrictions on kernelW and strideW; Based on this, if KernelH == InputH and pad_H is 0, then kernelH and strideH also have no [0, 255] restrictions |
| BatchNormalization | epsilon: Unlimited momentum: Not supported training_mode: Does not support non-0 is_test: Does not support non-0 spatial: Does not support non-1 |
| Cast | to: Supports float32/float64/int64/int32/bool saturate: Not supported |
| Ceil | Unlimited |
| Clip | Unlimited |
| Concat | 最大支持10000个tensor concat |
| Constant | Unlimited |
| ConstantOfShape | Unlimited |
| Conv | conv1d: All tensor size < 2^31 auto_pad: Supported, SAME_UPPER, SAME_LOWER or VALID dilations: Supported, two dimensions, both [0, 31], exceeding will be optimized internally group: Less than or equal to C kernel_shape: Supported, h * w < 100 pads: Supported, four dimensions, all [0,15], exceeding will generate a separate pad operator strides: Supported, two dimensions, both [0, 31] conv2d: All tensor size < 2^31 auto_pad: Supported, SAME_UPPER, SAME_LOWER or VALID dilations: Supported, two dimensions, both [0, 31], exceeding will be optimized internally group: Less than or equal to C kernel_shape: Supported, h * w < 100 pads: Supported, four dimensions, all [0,15], exceeding will generate a separate pad operator strides: Supported, two dimensions, both [0, 31] conv3d: All tensor size < 2^31 auto_pad: Supported, SAME_UPPER, SAME_LOWER or VALID dilations: Supported, two dimensions, both [0, 31], exceeding will be optimized internally group: Not supported kernel_shape: Supported, h * w < 100, d dimension Unlimited pads: Supported h, w, d three dimensions six directions, all [0, 15], exceeding will generate a separate pad operator strides: Supported h, w two dimensions, both [0, 31], d dimension Unlimited |
| ConvTranspose | All tensor size < 2^31 auto_pad: Supported, SAME_UPPER, SAME_LOWER or VALID dilations: Supported, two dimensions, both [0, 31] group: Less than or equal to C kernel_shape: Supported, h * w < 100 output_padding: Supported output_shape: Not supported pads: Supported strides: Supported, two dimensions |
| Cos | Unlimited |
| CumSum | exclusive: Only supports setting to 0 reverse: Only supports setting to 0 |
| DepthToSpace | blocksize: Supported, the input c dimension must be divisible by blocksize^2 mode: DCR or CRD |
| Div | Unlimited |
| Dropout | is_test: Not supported ratio: Not supported seed: Not supported |
| Einsum | equation: Unlimited Supports both single and double operands, does not support expressions in omitted dimension format |
| Elu | Unlimited |
| Equal | Unlimited |
| Erf | Unlimited |
| Exp | Unlimited |
| Expand | Unlimited |
| Flatten | Unlimited |
| Floor | Unlimited |
| GRU | activation_alpha: Not supported activation_beta: Not supported activations: Only supports sigmoid/tanh clip: Not supported direction: Supports forward and bidirectional layout: Only supports 0 linear_before_offset: Supports 0 and 1 sequence_lens in the input does not support variable |
| Gather | axis: Unlimited indices input supports const and variable |
| GatherElements | axis: Unlimited indices input supports const and variable |
| GatherND | axis: Unlimited indices input supports const and variable |
| Gelu | approximate: Supports None and tanh |
| Gemm | alpha:Unlimited beta:Unlimited transA:Unlimited transB:Unlimited |
| GlobalAveragePool | Unlimited |
| GlobalMaxPool | Unlimited |
| Greater | Unlimited |
| GreaterOrEqual | Unlimited |
| HardSigmoid | alpha:Unlimited beta:Unlimited |
| HardSwish | Unlimited |
| Identity | This operator will be removed during the conversion process |
| InstanceNormalization | epsilon:Unlimited |
| LSTM | activation_alpha: Not supported activation_beta: Not supported activations: Only supports sigmoid/tanh clip: Not supported direction: Only supports forward and bidirectional input_forget: Only supports 0 layout: Only supports 0 sequence_lens in the input does not support variable |
| LayerNormal | axis: Does not support 0 epsilon: Unlimited stash_type: Not supported |
| LayerNormalization | axis: Does not support 0 epsilon: Unlimited stash_type: Not supported |
| LeakyRelu | alpha:Unlimited |
| Less | Unlimited |
| LessOrEqual | Unlimited |
| Log | Unlimited |
| LogSoftmax | Unlimited |
| Logcompress | Unlimited |
| MatMul | Unlimited |
| Max | Unlimited |
| MaxPool | auto_pad: Supported, SAME_UPPER, SAME_LOWER or VALID ceil_mode: Supported kernel_shape: Supported pads: Supported strides: Supported storage_order: Not supported 1, calculated according to 0 If the kernel size is h*w, it must meet FilterW <= 255, FilterH <= 255 |
| MeanVarianceNormalization | Input only supports four dimensions axes: Unlimited |
| Min | Unlimited |
| Mod | Unlimited fmod can only be 0 |
| Mul | Unlimited |
| Neg | Unlimited |
| Not | Unlimited |
| Or | Unlimited |
| PRelu | Unlimited |
| Pad | mode: Supports constant/reflect value: Unlimited Does not support axes as input |
| Pow | Unlimited |
| RNN | activation_alpha: Not supported activation_beta: Not supported activations: Only supports tanh clip: Not supported direction: Only supports forward and bidirectional layout: Only supports 0 sequence_lens in the input only supports empty tensor, does not support variable |
| Range | Unlimited |
| Reciprocal | Unlimited |
| ReduceL2 | axes: Unlimited keepdims: Unlimited noop_with_empty_axes: Only supports 0 |
| ReduceMax | axes: Unlimited keepdims: Unlimited noop_with_empty_axes: Only supports 0 |
| ReduceMean | axes: Unlimited keepdims: Unlimited noop_with_empty_axes: Only supports 0 |
| ReduceMin | axes: Unlimited keepdims: Unlimited noop_with_empty_axes: Only supports 0 |
| ReduceSum | axes: Unlimited keepdims: Unlimited noop_with_empty_axes: Only supports 0 |
| Relu | Unlimited |
| Reshape | allowzero: Only supports 0, does not support 0 values in the output shape |
| Resize | Only supports resizing for hw antialias: Only supports 0 coordinate_transformation_mode: Supports align_corners/asymmetric/half_pixel/pytorch_half_pixel mode: Supports nearest or linear cubic_coeff_a: Not supported exclude_outside: Only supports 0 extrapolation_value: Not supported keep_aspect_ratio_policy: Not supported nearest_mode: Supports, [round_prefer_floor, floor, round_prefer_ceil] |
| Round | Unlimited |
| Scatter | Unlimited |
| ScatterElements | indices support is const tensor and variable tensor axis: Unlimited reduction: Only supports None |
| ScatterND | indices support is const tensor and variable tensor reduction: Only supports None |
| Shape | end:Unlimited start:Unlimited |
| Sigmoid | Unlimited |
| Sign | Unlimited |
| Sin | Unlimited |
| Slice | axes:Unlimited ends:Unlimited starts:Unlimited |
| Softmax | Unlimited |
| Softplus | Unlimited |
| SpaceToDepth | blocksize:Unlimited |
| Split | axis: Unlimited split: Supports up to a maximum of 10000 num_outputs: Supported |
| Sqrt | Unlimited |
| Squeeze | axes:Unlimited |
| Sub | Unlimited |
| Sum | Only supports two inputs |
| Tanh | Unlimited |
| Tile | Unlimited |
| TopK | axis: Unlimited largest: Only supports 1 sorted: Only supports 1 k: Unlimited |
| Transpose | perm:Unlimited |
| Unsqueeze | Unlimited |
| Upsample | Only supports Upsample in the HW dimension, and the scale must be the same mode: Supports nearest and linear height_scale: Unlimited width_scale: Unlimited scales: Unlimited |
| Where | Unlimited |
4. SGS_CHALK支持算子¶
SGS_CHALK各算子具体使用方法请参考: sgs_chalk模块API
| 算子 | 备注 |
|---|---|
| Abs | |
| Add | |
| Alpha_Blending | |
| ArgMin | |
| Argmax | |
| Atan | |
| Atan2 | |
| AveragePool2d | |
| AveragePool3d | |
| BatchMatMul | |
| BatchToSpaceND | |
| BoxDecoder | |
| BoxDecoder2 | |
| Cast | |
| Ceil | |
| Clip | |
| Concatenation | |
| CondGreat | |
| CondLess | |
| Conv2d | |
| Conv3d | |
| Conv3dImageConcat | |
| Cos | |
| Cumsum | |
| CustomNotEqual | |
| CustomPow | |
| CustomizedMaxpool2d | |
| DepthWiseConv2d | |
| Dilation | |
| Div | |
| Elu | |
| Equal | |
| Erf | |
| Exp | |
| Expand_dims | |
| Fill | |
| Floor | |
| Fullyconnected | |
| GRU | |
| Gather | |
| GatherElements | |
| GatherND | |
| Gelu | |
| Greater | |
| GreaterEqual | |
| GroupConv2d | |
| HardSwish | |
| Input | |
| Instancenorm | |
| L2Norm | |
| LSTM | |
| LSTM_caffe | |
| Layernorm | |
| LeakyRelu | |
| Less | |
| LessEqual | |
| Log | |
| Logcompress | |
| LogicalAnd | |
| LogicalNot | |
| LogicalOr | |
| Logistic | |
| MaxPool2d | |
| MaxPool3d | |
| Maximum | |
| Mean | |
| MeanVarianceNorm | |
| Minimum | |
| MirrorPad | |
| Mod | |
| Mul | |
| MultiplyAdd | |
| Negative | |
| NotEqual | |
| Pack | |
| Pad | |
| PhaseModify | |
| PostProcess_Max | |
| PostProcess_Unpack | |
| Prelu | |
| RNN | |
| RSqrt | |
| Range | |
| Reciprocal | |
| ReduceMax | |
| ReduceMin | |
| Relu | |
| Relu1 | |
| Relu6 | |
| Relu_N1_TO_1 | |
| Reshape | |
| ResizeBilinear | |
| ResizeNearestNeighbor | |
| RoiPooling | |
| RootSumSquares2 | |
| Round | |
| ScatterElements | |
| ScatterND | |
| Score_Filter | |
| Select | |
| Shape | |
| Sign | |
| Silu | |
| Sin | |
| Slice | |
| Softmax | |
| Softplus | |
| SpaceToBatchND | |
| Split | |
| Split_V | |
| Sqrt | |
| Square | |
| Squeeze | |
| StridedSlice | |
| Sub | |
| Sum | |
| TFLite_Detection_NMS | |
| Tanh | |
| Tile | |
| TopK | |
| Transpose | |
| TransposeConv2d | |
| Unpack | |
| WiggleErr |
5. IPU Toolchain对模型的限制¶
对于指定维度的Softmax,我们只支持对最内维度的操作(多余多维Tensor的Softmax运算,我们只支持Softmax制定在最内维度做)。
除第一层Conv外,其他层的Conv DI维度(即NHWC 中C这个维度)越大效率会越高,最大支援2048。
Math类算子(包括Add、Sub、Mul、Div等元素操作的算子),如果右操作数是scaler(单个数字) 或者 1 维向量(HW维度数据相同,C维度不同),效率会更高。
网络结构中尽量减少一个算子的输出被多个算子作为输入的情况,如ResNet的残差结构,GoogLeNet的Inception模块等。可参考构建BW友好型模型
6. 模型性能优化规则¶
(1)对于卷积的性能优化
kernel size 3x3 最好,特别对于首层。
kernel size 1x1 的时候,input tensor 最内维度shape值对齐到16 最好。
(2)对于DMA算子
concatenation算子比pack算子性能更好。
split比slice算子性能更好。
尽量减少在最内维上做transpose。
单口elementwise 算子的const 操作数最好是右操作数,即input[1]。
(3)综合部分
Tensor的维度为4最好。
Tensor最内维的shape值对齐到32最好。
Softmax最好只对最内维度操作。
ReduceMax、ReduceMin、ReduceSum最好坍塌的纬度是相邻的。
(4)构建BW友好的AI模型
BW友好的AI模型指模型数据尽可能不占用系统总线BW资源,BW计算公式如下:
BW = Input BW + Output BW + Const BW + Variable BW
其中,可以通过减少variable bw来提升模型性能,variable bw将受以下两点影响:
(1) tensor数据量太大
(2) tensor的生命周期太长
示例一:BW友好型
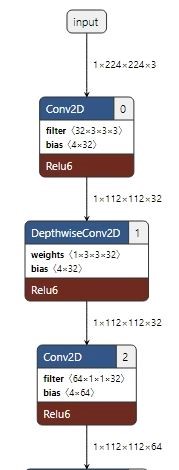
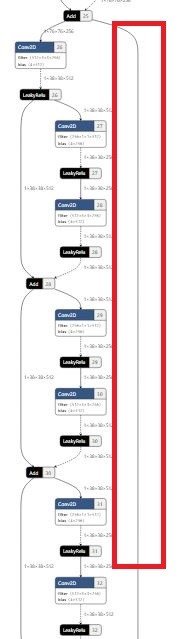
示例二:tensor的生命周期太长
示例三:tensor数据量太大
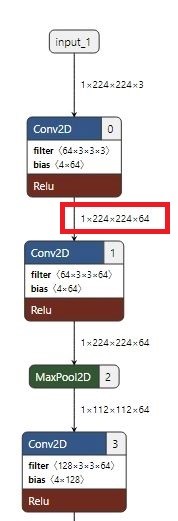
上图展示了三种常见的模型结构图,其中图一所示的结构符合模型优化规则,图二、图三所示的结构将影响模型性能。构建模型时请尽可能减少图二、图三结构的使用。