8. 常见问题解答
1. 环境常见问题¶
Docker都可以在Ubuntu或是Windows下设置吗?最小内存需求?
是的,建议使用docker,所需的最小内存至少为32G,如果内存只是刚好够用,在做calibration时使用太多的process运行时,可能会产生非预期的错误而被中断掉。目前开发人员的操作环境都是在Ubuntu18.04。Windows的docker可能运行也没有问题,但实际使用上我们并不确定Windows下建立的docker环境不会遇到问题。
2. 模型转换常见问题¶
为什么模型转换时报ValueError: Message onnx.ModelProto exceeds maximum protobuf size of 2GB: 2714769235?
原始onnx模型转换前,需要使用onnxsim 或者 onnxslim 工具对原始模型结构优化,同时模型转换时需要在ConvertTool.py 命令行中添加 --skip_simplify 参数。
可以使用IPU_SDK转换工具直接转换INT8的模型吗?
当前不支援直接输入IPU Toolchain的量化定点网络模型,模型必须从浮点开始转换。可以使用量化导入工具将已有量化信息导入到模型中。
为什么input_config.ini中设置了dequantizations为FALSE,在PC仿真时仍然输出浮点数?
input_config.ini中的dequantizations配置成FALSE后是simulator.py完成了将int16输出结果乘scale的过程。配置成TRUE,会在转换Fixed模型时在输出增加Fix2float算子,此时模型直接输出浮点数据。还可以使用calibrator_custom.fixed_simulator创建定点模型的实例,通过get_output_details的方法查看网络输出的数据类型。
为什么从浮点模型转到定点模型的时候,一直卡在Start to analysis model...?
遇到这个情况,请检查该进程的CPU占用率,如果一直接近100%,表示该模型正在转换中。如果一直接近0%,请终止该进程,使用一张图片重新量化看是否有报错信息。
为什么用DumpDebug工具比较有精度损失的定点模型和浮点模型时,输出的log中不能显示出所有层的比较结果?
这是由于DebugConfig.txt中的disableDomainFuseOps没有开启,导致有些op融合。请先将DebugConfig.txt拷贝到执行目录中,并将disableDomainFuseOps开启,并重新转换模型后再进行simulator生成sigma_outtensor_dump.bin文件。
Note
- 生成实际部署的offline模型时,需要关闭disableDomainFuseOps,否则会影响模型性能。
为什么用DumpDebug工具比较时,会出现 write file fail...?
这是由于DebugConfig.txt中path=配置的路径不存在,请检查配置的路径并配置存在的绝地路径。默认路径为用户根目录。
3. 开发板端常见问题¶
在板上运行网络模型输出数据怎么和PC上不一样?
请参考板端精度问题分析。
在板上输出浮点数全部是IPU完成的吗?
IPU可以通过增加Fix2float算子完成int16乘scale到float32数据的转换。只需网络转换时input_config.ini中dequantizations设为TRUE,在转到Fixed模型后会在模型对应的输出增加Fix2float算子。
运行时,模型占用的内存如何查看?
cat /proc/mi_modules/mi_sys_mma/mma_heap_name0参看以下解释
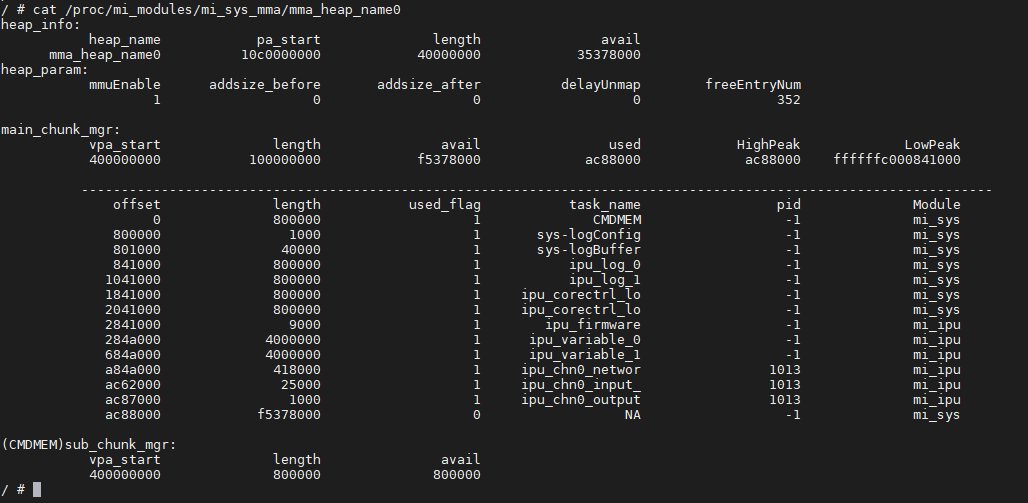
ipu_variable:推理过程中ipu核临时使用的内存
ipu_log:存储log使用的内存
ipu_chn0_networ:channel 0装载网络模型使用的内存
ipu_chn0_input_:channel 0 输入tensor占用的内存(多个则代表有多个输入tensor可同时使用)
ipu_chn0_output:channel 0输出tensor占用的内存(多个则代表有多个输出tensor可同时使用)
4. 其他常见问题¶
网络应该如何设计,能在芯片上高效执行?
需要说明的是,SGS_IPU_Toolchain转换后的模型默认数据排布为NHWC。 卷积方面:卷积的输入shape的C越大,HW越小,卷积的效率越高。硬件能直接支持kernel size为3x3的Depthwise卷积,其他size的kernel将转换为非Depthwise卷积计算。 其他层:其他层的C维度最好是16的整数倍,都能够加速运算,特别是Gather、Unpack、Pack、Concat、Reshape、Slice、Tile、Tanspose、Pad、Split等算子加速十分明显。
网络输入的图片数据排布是怎样的?
需要说明的是,SGS_IPU_Toolchain转换后的模型默认数据排布为NHWC。因此如果是RGB通道顺序的图片输入模型,图片数据排布是……RGBRGB……。如果是BGR通道顺序的图片输入模型,图片数据排布是……BGRBGR……。
如何查看IPU频率
cat /sys/dla/freq
或者
cat cat /proc/mi_modules/mi_ipu/debug_hal/freq
Note
- 不同chip,查看freq的命令可能不一样。
如何查看IPU DRAM 信息
cat /sys/devices/system/miu/miu0/dram_info