WeSpeaker
1 概述¶
1.1 背景介绍¶
本次开源的声纹识别算法来源于wenet社区发布的wespeaker, 具有高质量、轻量级、面向产品等特点。
详情可参考wespeaker官方链接:
https://github.com/wenet-e2e/wespeaker
我们所采用是基于CNCeleb训练的ResNet34 Checkpoint Model, 下载地址为:
https://huggingface.co/Wespeaker/wespeaker-cnceleb-resnet34/tree/main
1.2 使用说明¶
Linux SDK-alkaid中默认带了已经预先转换好的离线模型及板端示例, 相关文件路径如下:
-
板端示例程序路径
Linux_SDK/sdk/verify/opendla/source/speaker -
板端离线模型路径
Linux_SDK/project/board/${chip}/dla_file/ipu_open_models/asr/speaker_sim.img -
板端测试音频路径
Linux_SDK/sdk/verify/opendla/source/resource/gallery/examples_BAC009S0913W0133.wav Linux_SDK/sdk/verify/opendla/source/resource/query/examples_BAC009S0764W0228.wav Linux_SDK/sdk/verify/opendla/source/resource/query/examples_BAC009S0764W0328.wav Linux_SDK/sdk/verify/opendla/source/resource/query/examples_BAC009S0913W0133.wav Linux_SDK/sdk/verify/opendla/source/resource/query/examples_BAC009S0913W0282.wav Linux_SDK/sdk/verify/opendla/source/resource/query/spk_0.wav Linux_SDK/sdk/verify/opendla/source/resource/query/spk_1.wav Linux_SDK/sdk/verify/opendla/source/resource/query/spk_2.wav
如果用户不需要转换模型可直接跳转至第3章节。
2 模型转换¶
2.1 onnx模型转换¶
-
python环境搭建
$conda create -n wespeaker python=3.10 $conda activate wespeaker $git clone https://github.com/wenet-e2e/wespeaker.git $conda install pytorch=1.12.1 torchaudio=0.12.1 cudatoolkit=11.3 -c pytorch -c conda-forge $cd wespeaker $pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple $pre-commit install # for clean and tidy code注意:这里提供的python环境搭建, 仅作为参考示例, 具体搭建过程请参考官方源码运行教程:
https://github.com/wenet-e2e/wespeaker/blob/master/README.md -
模型测试
-
编写模型测试脚本
predict.pyimport wespeaker model = wespeaker.load_model('chinese') embedding = model.extract_embedding('audio.wav') utt_names, embeddings = model.extract_embedding_list('wav.scp') similarity = model.compute_similarity('audio1.wav', 'audio2.wav') diar_result = model.diarize('audio.wav') -
运行模型测试脚本, 确保wespeaker环境配置正确。
$python predict.py
-
-
模型导出
- 运行模型转换脚本, 会在当目录下生成speaker_sim.onnx模型
python wespeaker/bin/export_onnx.py \\ --config model_cnresnet34/config.yaml \\ --checkpoint model_cnresnet34/avg_model.pt \\ --output_model model_cnresnet34/speaker_sim.onnx
- 运行模型转换脚本, 会在当目录下生成speaker_sim.onnx模型
2.2 离线模型转换¶
2.2.1 预&后处理说明¶
-
预处理
语音输入到模型之前, 需要将语音wav转换为fbank。转换成功的speaker_sim.onnx模型输入信息如下图所示, 要求输入的fbank长度为 (1, 200, 80)。其中, 200为时间序列长度, 80为通道数大小。
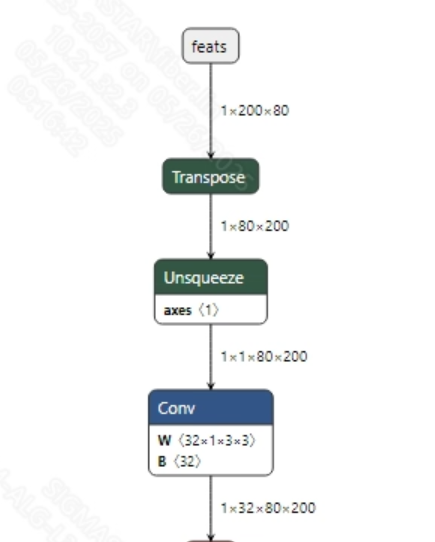
-
后处理
声纹识别模型没有后处理操作, 提取音频特征后主要是用于对比不同音频之间的相似度。模型输出信息如下所示:
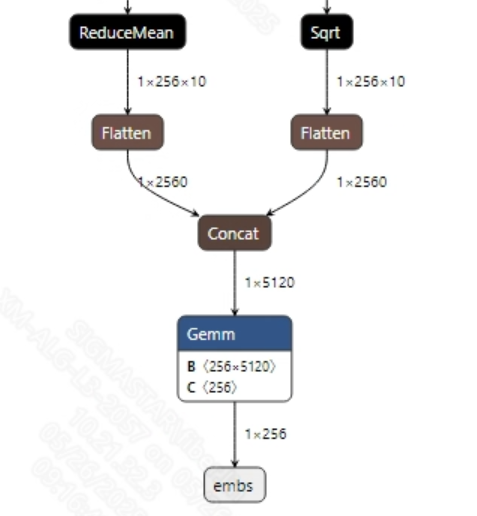
2.2.2 offline模型转换流程¶
注意:1)OpenDLAModel对应的是压缩包image-dev_model_convert.tar解压之后的smodel文件。2)转换命令需要在docker环境下运行, 请先根据Docker开发环境教程, 加载SGS Docker环境。
-
拷贝onnx模型到转换代码目录
$cp model_cnresnet34/speaker_sim.onnx OpenDLAModel/speaker/resnet/onnx -
转换命令
$cd IPU_SDK_Release/docker $bash run_docker.sh #进入到docker环境下的OpenDLAModel目录 $cd /work/SGS_XXX/OpenDLAModel $bash convert.sh -a speaker/resnet -c config/speaker_resnet.cfg -p SGS_IPU_Toolchain(绝对路径) -s false -
最终生成的模型地址
output/${chip}_${时间}/speaker_sim.img output/${chip}_${时间}/speaker_sim_fixed.sim output/${chip}_${时间}/speaker_sim_float.sim
2.2.3 关键脚本参数解析¶
- input_config.ini
[INPUT_CONFIG]
inputs=feats; #onnx 输入节点名称, 如果有多个需以“,”隔开;
input_formats=RAWDATA_F32_NHWC; #板端输入格式, 可以根据onnx的输入格式选择, 例如float:RAWDATA_F32_NHWC, int32:RAWDATA_S16_NHWC;
quantizations=TRUE; #打开输入量化, 不需要修改;
[OUTPUT_CONFIG]
outputs=embs; #onnx 输出节点名称, 如果有多个需以“,”隔开;
dequantizations=FALSE; #是否开启反量化, 根据实际需求填写, 建议为TRUE。设为False, 输出为int16; 设为True, 输出为float32
[CONV_CONFIG]
#input_format="ALL_INT16";
- speaker_resnet.cfg
[SPEAKER]
CHIP_LIST=pcupid #平台名称, 必须和板端平台一致, 否则模型无法运行
Model_LIST=speaker_sim #输入onnx模型名称
INPUT_SIZE_LIST=0 #模型输入分辨率
INPUT_INI_LIST=input_config.ini #配置文件
CLASS_NUM_LIST=0 #填0即可
SAVE_NAME_LIST=speaker_sim.img #输出模型名称
QUANT_DATA_PATH=image_lists #量化数据路径
2.3 模型仿真¶
-
获取float/fixed/offline模型输出
$bash convert.sh -a speaker/resnet -c config/speaker_resnet.cfg -p SGS_IPU_Toolchain(绝对路径) -s true执行上述命令后, 会默认将
float模型的输出tensor保存到speaker/resnet/log/output路径下的txt文件中。此外, 在speaker/resnet/convert.sh脚本中也提供了fixed和offline的仿真示例, 用户在运行时可以通过打开注释代码块, 分别获取fixed和offline模型输出。 -
模型精度对比
在保证输入和上述模型相同的情况下, 进入2.1章节搭建好的环境, 在
wespeaker/predict.py文件中第5行处添加打印:print(embedding)获取pytorch模型对应节点的输出tensor, 进而和float、fixed、offline模型进行对比。此外需要特别注意的是, 原始模型的输出格式是
NCHW, 而float/fixed/offline模型输出的格式是NHWC。
3 板端部署¶
3.1 程序编译¶
示例程序编译之前需要先根据板子(nand/nor/emmc, ddr型号等)选择deconfig进行sdk整包编译, 具体可以参考alkaid sdk sigdoc《开发环境搭建》文档。
-
编译板端speaker示例。
$cd sdk/verify/opendla $make clean && make source/speaker -j8 -
最终生成的可执行文件地址
sdk/verify/opendla/out/${AARCH}/app/prog_speaker
3.2 运行文件¶
运行程序时, 需要先将以下几个文件拷贝到板端
- prog_speaker
- gallery/*.wav
- query/*.wav
- speaker_sim.img
3.3 运行说明¶
-
Usage:
./prog_speaker gallery/ query/ model(执行文件使用命令) -
Required Input:
- gallery: 候选音频文件夹
- query:查询音频文件夹
- model: offline模型路径
-
Typical Output:
./prog_speaker gallery/ query/ models/speaker_sim.img client [815] connected, module:ipu gallery index: 0 query match scores: 0.560817 query match scores: 0.571763 query match scores: 0.576536 query match scores: 0.954973 query match scores: 0.821015 query match scores: 0.555230 query match scores: 0.579051 query match scores: 0.570105 ------shutdown IPU0------ client [815] disconnected, module:ipu