Vad
1 概述¶
1.1 背景介绍¶
vad是语音活动性检测算法, 能够识别出音频中的人声片段, 可以作为语音识别、说话人识别任务的前置模块。我们采用NVIDIA开源的NeMo-Vad模型进行部署, 有关模型的详细信息可访问:
https://github.com/NVIDIA/NeMo/tree/v1.20.0
模型下载地址为:
https://catalog.ngc.nvidia.com/orgs/nvidia/teams/nemo/models/vad_multilingual_marblenet/files
1.2 使用说明¶
Linux SDK-alkaid中默认带了已经预先转换好的离线模型及板端示例, 相关文件路径如下:
-
板端示例程序路径
Linux_SDK/sdk/verify/opendla/source/vad/nemo -
板端离线模型路径
Linux_SDK/project/board/${chip}/dla_file/ipu_open_models/vad/vad_sim.img -
板端测试音频路径
Linux_SDK/sdk/verify/opendla/source/resource/BAC009S0764W0121.wav
如果用户不需要转换模型可直接跳转至第3章节。
2 模型转换¶
2.1 onnx模型转换¶
-
python环境搭建
$conda create --name nemo python==3.10.12 $conda activate nemo $conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch $pip install nemo_toolkit['all']注意:我们是基于nemo-v1.20.0版本上进行开发的, 这里提供的python环境搭建, 仅作为参考示例, 具体搭建过程请参考官方源码运行教程:
https://github.com/NVIDIA/NeMo/tree/v1.20.0 -
模型测试
运行推理脚本, 确保nemo环境配置正确。
$cd NeMo $python ./examples/asr/speech_classification/frame_vad_infer.py \ --config-path="./examples/asr/conf/vad" \ --config-name="frame_vad_infer_postprocess.yaml" \ -
模型导出
-
编写模型转换脚本
frame_vad_infer.py-
在
examples/asr/speech_classification/frame_vad_infer.py中第104行处添加:vad_model.export( './vad.onnx', dynamic_axes={}, input_example=[torch.rand((1, 400, 80)).cuda(), {"length":400}]) -
在
collections/asr/models/asr_model.py中第189行处添加:if instance(input, list): tmp = input input = tmp[0] length = tmp[1] if input.hap[2] == 80 and input.shape[1] == length: input = torch.transpose(input, 1, 2) -
在
collections/asr/models/asr_model.py第204行处修改:- 原始:
ret = dec_fun(encoder_states=encoder_output) - 修改: ret = dec_fun(hidden_states = encoder_output)
- 原始:
-
-
运行模型转换脚本
frame_vad_infer.py。$python ./examples/asr/speech_classification/frame_vad_infer.py \ --config-path="./examples/asr/conf/vad" \ --config-name="frame_vad_infer_postprocess.yaml" \
-
2.2 离线模型转换¶
2.2.1 预&后处理说明¶
-
预处理
语音输入到模型之前, 需要将语音wav转换为fbank。转换成功的vad_sim.onnx模型输入信息如下图所示, 要求输入的fbank长度为 (1, 400, 80)。其中, 400为时间序列长度, 80为通道数大小。
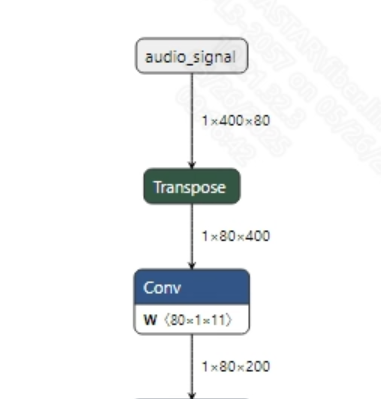
-
后处理
该模型没有后处理, 获取到输出的特征后, 再经过softmax操作, 可以获取当前输入token是否为有效音频的预测值。模型输出信息如下:
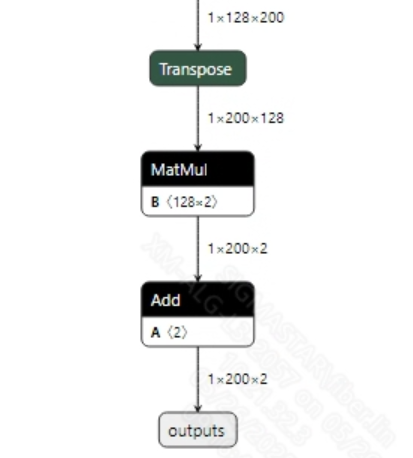
2.2.2 offline模型转换流程¶
注意:1)OpenDLAModel对应的是压缩包image-dev_model_convert.tar解压之后的smodel文件。2)转换命令需要在docker环境下运行, 请先根据Docker开发环境教程, 加载SGS Docker环境。
-
拷贝onnx模型到转换代码目录
$cp vad_sim.onnx OpenDLAModel/vad/nemo/onnx -
转换命令
$cd IPU_SDK_Release/docker $bash run_docker.sh #进入到docker环境下的OpenDLAModel目录 $cd /work/SGS_XXX/OpenDLAModel $bash convert.sh -a vad/nemo -c config/vad_nemo.cfg -p SGS_IPU_Toolchain(绝对路径) -s false -
最终生成的模型地址
output/${chip}_${时间}/vad_sim.img output/${chip}_${时间}/vad_sim_fixed.sim output/${chip}_${时间}/vad_sim_float.sim
2.2.3 关键脚本参数解析¶
- input_config.ini
[INPUT_CONFIG]
inputs=audio_signal; #onnx 输入节点名称, 如果有多个需以“,”隔开;
input_formats=RAWDATA_FP32_NHWC; #板端输入格式, 可以根据onnx的输入格式选择, 例如float:RAWDATA_F32_NHWC, int32:RAWDATA_S16_NHWC;
quantizations=TRUE; #打开输入量化, 不需要修改;
[OUTPUT_CONFIG]
outputs=outputs; #onnx 输出节点名称, 如果有多个需以“,”隔开;
dequantizations=TRUE; #是否开启反量化, 根据实际需求填写, 建议为TRUE。设为False, 输出为int16; 设为True, 输出为float32
- vad_nemo.cfg
[COMFORMER]
CHIP_LIST=pcupid #平台名称, 必须和板端平台一致, 否则模型无法运行
Model_LIST=vad_sim #输入onnx模型名称
INPUT_SIZE_LIST=0 #模型输入分辨率
INPUT_INI_LIST=input_config.ini #配置文件
CLASS_NUM_LIST=0 #填0即可
SAVE_NAME_LIST=vad_sim.img #输出模型名称
QUANT_DATA_PATH=image_lists.txt #量化数据路径
2.3 模型仿真¶
-
获取float/fixed/offline模型输出
$bash convert.sh -a vad/nemo -c config/vad_nemo.cfg -p SGS_IPU_Toolchain(绝对路径) -s true执行上述命令后, 会默认将
float模型的输出tensor保存到vad/nemo/log/output路径下的txt文件中。此外, 在vad/nemo/convert.sh脚本中也提供了fixed和offline的仿真示例, 用户在运行时可以通过打开注释代码块, 分别获取fixed和offline模型输出。 -
模型精度对比
在保证输入和上述模型相同的情况下, 进入2.1章节搭建好的环境, 在
examples/asr/asr_vad/speech_to_text_with_vad.py文件中第447行处添加打印:print(log_probs)即可获取pytorch模型对应节点的输出tensor, 进而和float、fixed、offline模型进行对比。此外需要特别注意的是, 原始模型的输出格式是
NCHW, 而float/fixed/offline模型输出的格式是NHWC。
3 板端部署¶
3.1 程序编译¶
示例程序编译之前需要先根据板子(nand/nor/emmc, ddr型号等)选择deconfig进行sdk整包编译, 具体可以参考alkaid sdk sigdoc《开发环境搭建》文档。
-
编译板端nemo示例。
$cd sdk/verify/opendla $make clean && make source/vad/nemo -j8 -
最终生成的可执行文件地址
sdk/verify/opendla/out/${AARCH}/app/prog_vad_nemo
3.2 运行文件¶
运行程序时, 需要先将以下几个文件拷贝到板端
- prog_vad_nemo
- BAC009S0764W0121
- vad_sim.img
3.3 运行说明¶
-
Usage:
./prog_vad_nemo wav model(执行文件使用命令)- wav: 音频文件
- model: offline模型
-
Typical Output:
./prog_vad_nemo resource/BAC009S0764W0121.wav models/vad_sim.img client [922] connected, module:ipu is_speech score: 0.001206 is_speech score: 0.002193 is_speech score: 0.001267 is_speech score: 0.001172 is_speech score: 0.001315 is_speech score: 0.001187 is_speech score: 0.001588 is_speech score: 0.001541 is_speech score: 0.002397 is_speech score: 0.001925 is_speech score: 0.004228 is_speech score: 0.003051 is_speech score: 0.005933 is_speech score: 0.004191 is_speech score: 0.005690 is_speech score: 0.004748 is_speech score: 0.009524 is_speech score: 0.005953 is_speech score: 0.009928 is_speech score: 0.017336 is_speech score: 0.207253 is_speech score: 0.390963 is_speech score: 0.838701 is_speech score: 0.880120 is_speech score: 0.978352 is_speech score: 0.991667 is_speech score: 0.997704 is_speech score: 0.996953 is_speech score: 0.999195 is_speech score: 0.998785 is_speech score: 0.999110 is_speech score: 0.999063 is_speech score: 0.999097 is_speech score: 0.999155 is_speech score: 0.999170 is_speech score: 0.999101 is_speech score: 0.999304 is_speech score: 0.999292 is_speech score: 0.999446 is_speech score: 0.999426 is_speech score: 0.999559 is_speech score: 0.999268 is_speech score: 0.999304 is_speech score: 0.998892 is_speech score: 0.999053 is_speech score: 0.998227 is_speech score: 0.998460 is_speech score: 0.998189 is_speech score: 0.998425 is_speech score: 0.998025 is_speech score: 0.998069 is_speech score: 0.998468 is_speech score: 0.999088 is_speech score: 0.999029 is_speech score: 0.999137 is_speech score: 0.999095 is_speech score: 0.999192 is_speech score: 0.999230 is_speech score: 0.999287 is_speech score: 0.999368 is_speech score: 0.999313 is_speech score: 0.999182 is_speech score: 0.999272 is_speech score: 0.999301 is_speech score: 0.999371 is_speech score: 0.999323 is_speech score: 0.999371 is_speech score: 0.999400 is_speech score: 0.999420 is_speech score: 0.999357 is_speech score: 0.999335 is_speech score: 0.999302 is_speech score: 0.999152 is_speech score: 0.998994 is_speech score: 0.999222 is_speech score: 0.999228 is_speech score: 0.999421 is_speech score: 0.999515 is_speech score: 0.999520 is_speech score: 0.999449 is_speech score: 0.999450 is_speech score: 0.999400 is_speech score: 0.999372 is_speech score: 0.999289 is_speech score: 0.999198 is_speech score: 0.999097 is_speech score: 0.999022 is_speech score: 0.999040 is_speech score: 0.998885 is_speech score: 0.998684 is_speech score: 0.998773 is_speech score: 0.998566 is_speech score: 0.998348 is_speech score: 0.998506 is_speech score: 0.998509 is_speech score: 0.998559 is_speech score: 0.998362 is_speech score: 0.998425 is_speech score: 0.998132 is_speech score: 0.998449 is_speech score: 0.997921 is_speech score: 0.998176 is_speech score: 0.998372 is_speech score: 0.998765 is_speech score: 0.998756 is_speech score: 0.998616 is_speech score: 0.998536 is_speech score: 0.998450 is_speech score: 0.998342 is_speech score: 0.998394 is_speech score: 0.998035 is_speech score: 0.998153 is_speech score: 0.998049 is_speech score: 0.997196 is_speech score: 0.996593 is_speech score: 0.996181 is_speech score: 0.996602 is_speech score: 0.996609 is_speech score: 0.996776 is_speech score: 0.996258 is_speech score: 0.997197 is_speech score: 0.996720 is_speech score: 0.997739 is_speech score: 0.996624 is_speech score: 0.997697 is_speech score: 0.997436 is_speech score: 0.997792 is_speech score: 0.997465 is_speech score: 0.997800 is_speech score: 0.997511 is_speech score: 0.998078 is_speech score: 0.997501 is_speech score: 0.997395 is_speech score: 0.996318 is_speech score: 0.997522 is_speech score: 0.997541 is_speech score: 0.998257 is_speech score: 0.998209 is_speech score: 0.998666 is_speech score: 0.998414 is_speech score: 0.998512 is_speech score: 0.998298 is_speech score: 0.998064 is_speech score: 0.998181 is_speech score: 0.998808 is_speech score: 0.998935 is_speech score: 0.998969 is_speech score: 0.999039 is_speech score: 0.999035 is_speech score: 0.999177 is_speech score: 0.999238 is_speech score: 0.999272 is_speech score: 0.999245 is_speech score: 0.999046 is_speech score: 0.998965 is_speech score: 0.998740 is_speech score: 0.998614 is_speech score: 0.998825 is_speech score: 0.998696 is_speech score: 0.998248 is_speech score: 0.996915 is_speech score: 0.995238 is_speech score: 0.991321 is_speech score: 0.992952 is_speech score: 0.989907 is_speech score: 0.990689 is_speech score: 0.987685 is_speech score: 0.988767 is_speech score: 0.987314 is_speech score: 0.982662 is_speech score: 0.969382 is_speech score: 0.934737 is_speech score: 0.890915 is_speech score: 0.838379 is_speech score: 0.761765 is_speech score: 0.678670 is_speech score: 0.611241 is_speech score: 0.554069 is_speech score: 0.497151 is_speech score: 0.406663 is_speech score: 0.329079 is_speech score: 0.229154 is_speech score: 0.143231 is_speech score: 0.102593 is_speech score: 0.054421 is_speech score: 0.035556 is_speech score: 0.016550 is_speech score: 0.010145 is_speech score: 0.006585 is_speech score: 0.004256 is_speech score: 0.003941 is_speech score: 0.002855 is_speech score: 0.002925 is_speech score: 0.002234 is_speech score: 0.002314 is_speech score: 0.001892 is_speech score: 0.002127 is_speech score: 0.001897 is_speech score: 0.003490 is_speech score: 0.002991 output size: 200 2 ------shutdown IPU1------ client [922] disconnected, module:ipu