PunctuationModel
1 概述¶
1.1 背景介绍¶
标点模型能够精准预测语音识别模型输出文本中的标点符号, 为语音识别模块提供有力支持, 使其输出的文本结果更具可读性。
详情可参考:
https://github.com/yeyupiaoling/PunctuationModel
我们使用的模型是基于上述github仓库自己训练的, 训练流程可以参考官方链接提供的训练教程。其中, 预训练模型下载地址如下:
https://huggingface.co/nghuyong/ernie-3.0-mini-zh/tree/main
1.2 使用说明¶
Linux SDK-alkaid中默认带了已经预先转换好的离线模型及板端示例, 相关文件路径如下:
-
板端示例程序路径
Linux_SDK/sdk/verify/opendla/source/llm/conformer_punc -
板端离线模型路径
Linux_SDK/project/board/${chip}/dla_file/ipu_open_models/asr/conformer_400x80.img(前置模型) Linux_SDK/project/board/${chip}/dla_file/ipu_open_models/llm/punc_sim100.img -
板端测试音频路径
Linux_SDK/sdk/verify/opendla/source/resource/BAC009S0764W0121.wav -
板端测试字典路径
Linux_SDK/sdk/verify/opendla/source/resource/units_asr_punc_lm.txt
如果用户不需要转换模型可直接跳转至第3章节。
2 模型转换¶
2.1 onnx模型转换¶
-
python环境搭建
$conda create -n punc python==3.9 $conda activate punc $conda install paddlepaddle-gpu==2.3.2 cudatoolkit=10.2 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/ $git clone https://github.com/yeyupiaoling/PunctuationModel.git $cd PunctuationModel $python -m pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/注意:这里提供的python环境搭建, 仅作为参考示例, 具体搭建过程请参考官方源码运行教程:
https://github.com/yeyupiaoling/PunctuationModel?tab=readme-ov-file -
模型测试
运行推理脚本, 需要将训练好的模型
pun_models放到models目录下$mkdir models $cp -r pun_models ./models $python infer.py -
模型导出
-
安装依赖库
$pip install onnx -i https://pypi.tuna.tsinghua.edu.cn/simple $pip install onnx-simplifier -i https://pypi.tuna.tsinghua.edu.cn/simple $pip install onnxruntime -i https://pypi.tuna.tsinghua.edu.cn/simple -
编写模型转换脚本
export_onnx_model.pyimport argparse import functools import os import shutil import paddle from paddle.static import InputSpec from utils.logger import setup_logger from utils.model import ErnieLinearExport from utils.utils import add_arguments, print_arguments import numpy as np import onnx import onnxruntime from onnxsim import simplify logger = setup_logger(__name__) parser = argparse.ArgumentParser(description=__doc__) add_arg = functools.partial(add_arguments, argparser=parser) add_arg('punc_path', str, 'dataset/punc_vocab3', '标点符号字典路径') add_arg('model_path', str, 'models/iwslt2012_mini_punc3/best_checkpoint', '加载检查点的目录') add_arg('infer_model_path', str, 'models/iwslt2012_mini_punc3/pun_models', '保存的预测的目录') add_arg('pretrained_token', str, 'pretrained/ernie-3.0-mini-zh', '使用的ERNIE模型权重') add_arg('input_len', int, 100, '输入长度') args = parser.parse_args() print_arguments(args) def main(): os.makedirs(args.infer_model_path, exist_ok=True) with open(args.punc_path, 'r', encoding='utf-8') as f1, \ open(os.path.join(args.infer_model_path, 'vocab.txt'), 'w', encoding='utf-8') as f2: lines = f1.readlines() lines = [line.replace('\n', '') for line in lines] # num_classes为字符分类大小, 标点符号数量加1, 因为开头还有空格 num_classes = len(lines) + 1 f2.write(' \n') for line in lines: f2.write(f'{line}\n') model = ErnieLinearExport(pretrained_token=args.pretrained_token, num_classes=num_classes) model_dict = paddle.load(os.path.join(args.model_path, 'model.pdparams')) model.set_state_dict(model_dict) input_spec = [InputSpec(shape=(-1, -1), dtype=paddle.int64), InputSpec(shape=(-1, -1), dtype=paddle.int64)] paddle.jit.save(layer=model, path=os.path.join(args.infer_model_path, 'model'), input_spec=input_spec) with open(os.path.join(args.infer_model_path, 'info.json'), 'w', encoding='utf-8') as f: f.write(str({'pretrained_token': args.pretrained_token}).replace("'", '"')) logger.info(f'模型导出成功, 保存在:{args.infer_model_path}') # eport onnx onnx_save_path = os.path.join(args.infer_model_path, 'model.onnx') input_spec = paddle.static.InputSpec([1, args.input_len], 'int64', 'input') # 为模型指定输入的形状和数据类型 paddle.onnx.export(model, onnx_save_path, input_spec=[input_spec], opset_version=12) onnx_sim_save_path = os.path.join(args.infer_model_path, f'model_sim{args.input_len}.onnx') onnx_model = onnx.load(f"{onnx_save_path}.onnx") # load onnx model model_simp, check = simplify(onnx_model) assert check, "Simplified ONNX model could not be validated" onnx.save(model_simp, onnx_sim_save_path) # check check_input = np.random.randint(0, 3000, size=(1, args.input_len)).astype('int64') ort_sess = onnxruntime.InferenceSession(onnx_sim_save_path) ort_inputs = {ort_sess.get_inputs()[0].name: check_input} ort_outs = ort_sess.run(None, ort_inputs) model.eval() paddle_input = paddle.to_tensor(check_input) paddle_outs = model(paddle_input) np.testing.assert_allclose(paddle_outs.numpy(), ort_outs[0], rtol=1e-03, atol=1e-05) logger.info(f'onnx模型check出成功') logger.info(f'onnx模型导出成功, 保存在:{onnx_sim_save_path}') if __name__ == "__main__": main() -
运行模型转换脚本。
$python export_onnx_model.py $mv models/iwslt2012_mini_punc3/pun_models/model_sim100.onnx models/iwslt2012_mini_punc3/pun_models/punc_sim100.onnx
-
2.2 离线模型转换¶
2.2.1 预&后处理说明¶
-
预处理
标点模型的输入是token_id, 需要调用ErnieTokenizer对输入文本进行映射。标点模型的输入信息如下:

-
后处理
标点模型没有后处理, 模型的输出结果是输入100个token的预测结果, 即判断token后面是否添加标点。模型输出信息如下:
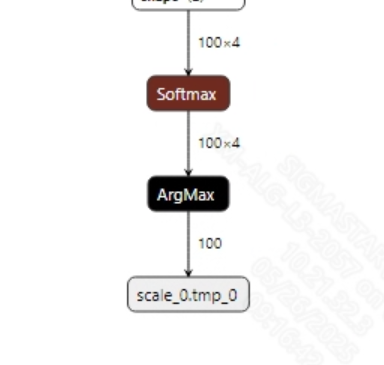
2.2.2 offline模型转换流程¶
注意:1)OpenDLAModel对应的是压缩包image-dev_model_convert.tar解压之后的smodel文件。2)转换命令需要在docker环境下运行, 请先根据Docker开发环境教程, 加载SGS Docker环境。
-
拷贝onnx模型到转换代码目录
$cp models/iwslt2012_mini_punc3/pun_models/punc_sim100.onnx OpenDLAModel/llm/punc/onnx -
转换命令
$cd IPU_SDK_Release/docker $bash run_docker.sh #进入到docker环境下的OpenDLAModel目录 $cd /work/SGS_XXX/OpenDLAModel $bash convert.sh -a llm/punc -c config/llm_punc.cfg -p SGS_IPU_Toolchain(绝对路径) -s false -
最终生成的模型地址
output/${chip}_${时间}/punc_sim100.img output/${chip}_${时间}/punc_sim100_fixed.sim output/${chip}_${时间}/punc_sim100_float.sim
2.2.3 关键脚本参数解析¶
- input_config.ini
[INPUT_CONFIG]
inputs=inputs; #onnx 输入节点名称, 如果有多个需以“,”隔开;
input_formats=RAWDATA_S16_NHWC; #板端输入格式, 可以根据onnx的输入格式选择, 例如float:RAWDATA_F32_NHWC, int32:RAWDATA_S16_NHWC;
quantizations=TRUE; #打开输入量化, 不需要修改;
[OUTPUT_CONFIG]
outputs=scale_0.tmp_0; #onnx 输出节点名称, 如果有多个需以“,”隔开;
dequantizations=TRUE; #是否开启反量化, 根据实际需求填写, 建议为TRUE。设为False, 输出为int16; 设为True, 输出为float32
- llm_punc.cfg
[COMFORMER]
CHIP_LIST=pcupid #平台名称, 必须和板端平台一致, 否则模型无法运行
Model_LIST=punc_sim100 #输入onnx模型名称
INPUT_SIZE_LIST=0 #模型输入分辨率
INPUT_INI_LIST=input_config.ini #配置文件
CLASS_NUM_LIST=0 #填0即可
SAVE_NAME_LIST=punc_sim100.img #输出模型名称, 可自行修改
QUANT_DATA_PATH=image_list.txt #量化数据路径
2.3 模型仿真¶
-
获取float/fixed/offline模型输出
$bash convert.sh -a llm/punc -c config/llm_punc.cfg -p SGS_IPU_Toolchain(绝对路径) -s true执行上述命令后, 会默认将
float模型的输出tensor保存到llm/punc/log/output路径下的txt文件中。此外, 在llm/punc/convert.sh脚本中也提供了fixed和offline的仿真示例, 用户在运行时可以通过打开注释代码块, 分别获取fixed和offline模型输出。 -
模型精度对比
在保证输入和上述模型相同的情况下, 进入2.1章节搭建好的环境, 在
PunctuationModel/utils/model.py脚本中第91行处之后添加打印:print(output_data)即可获取pytorch模型对应节点的输出tensor, 进而和float、fixed、offline模型进行对比。此外需要特别注意的是, 原始模型的输出格式是
NCHW, 而float/fixed/offline模型输出的格式是NHWC。
3 板端部署¶
3.1 程序编译¶
示例程序编译之前需要先根据板子(nand/nor/emmc, ddr型号等)选择deconfig进行sdk整包编译, 具体可以参考alkaid sdk sigdoc《开发环境搭建》文档。
-
编译板端punc示例。
$cd sdk/verify/opendla $make clean && make source/llm/conformer_punc -j8 -
最终生成的可执行文件地址
sdk/verify/opendla/out/${AARCH}/app/prog_llm_conformer_punc
3.2 运行文件¶
运行程序时, 需要先将以下几个文件拷贝到板端
- prog_llm_conformer_punc
- BAC009S0764W0121.wav
- units_asr_punc_lm.txt
- conformer_400x80.img
- punc_sim100.img
3.3 运行说明¶
该示例程序中将语音识别模型作为前置模块进行推理。
-
Usage:
./prog_llm_conformer_punc wav asr_model punc_model dict(执行文件使用命令) -
Required Input:
- wav: 输入音频
- asr_model: 语音识别模型
- punc_model: 标点识别模型
- dict: 字典
-
Typical Output:
./prog_llm_conformer_punc resource/BAC009S0764W0121.wav models/conformer_400x80.img models/punc_sim100.img resource/units_asr_punc_lm.txt client [809] connected, module:ipu num_frames: 418, sizeof(inputBuf): 8 am model preprocess time: 236.852000 ms am model invoke time: 96.343000 ms load dict... decode result... punc model invoke time: 10.579000 ms result: 甚至出现交易几乎停滞的情况。 ------shutdown IPU0------ client [809] disconnected, module:ipu